
Hackathon 0x09 – lib-common benchmarks
The goal was to develop benchmarks on a few of our core technologies in lib-common, in order to:
- Be able to compare the performances of our custom implementations with standard implementations.
- Be able to add automated tests on performance (e.g. adding non-regression tests to ensure that changes which seem to be harmless do not worsen performance).
Benchmark library
The first step was to develop a benchmark library; the success criteria we established were the following (compared to the already existing benchmarks in our code base):
- Ease writing of benchmarks
- Standardize output format
- Allow factorization of the use of external tools using benchmarks
And the result looks like this, on the user side:
ZBENCH_GROUP_EXPORT(bithacks) {
const size_t small_res = 71008;
ZBENCH(membitcount_naive_small) {
ZBENCH_LOOP() {
size_t res = 0;
ZBENCH_MEASURE() {
res = membitcount_check_small(&membitcount_naive);
} ZBENCH_MEASURE_END
if (res != small_res) {
e_fatal("expected: %zu, got: %zu", small_res, res);
}
} ZBENCH_LOOP_END
} ZBENCH_END
} ZBENCH_GROUP_END
If you are familiar with lib-common, you can see that it looks very similar
to the z test library.
The code is more or less translated as follows:
if (BENCHMARK_RUN_GROUP("bithacks") {
const size_t small_res = 71008;
if (BENCHMARK_RUN("membitcount_naive_small") {
for (int i = 0; i < BENCHMARKS_NB_RUNS; i++) {
size_t res = 0;
BENCHMARK_START();
res = membitcount_check_small(&membitcount_naive);
BENCHMARK_END();
if (res != small_res) {
e_fatal("expected: %zu, got: %zu", small_res, res);
}
}
}
}
First benchmark: printf
The first benchmark we did was the benchmark of libc snprintf against our own implementation of snprint (actually called isnprintf internally).
The result was not what we expected (the chart below shows the duration for one million calls to snprintf):
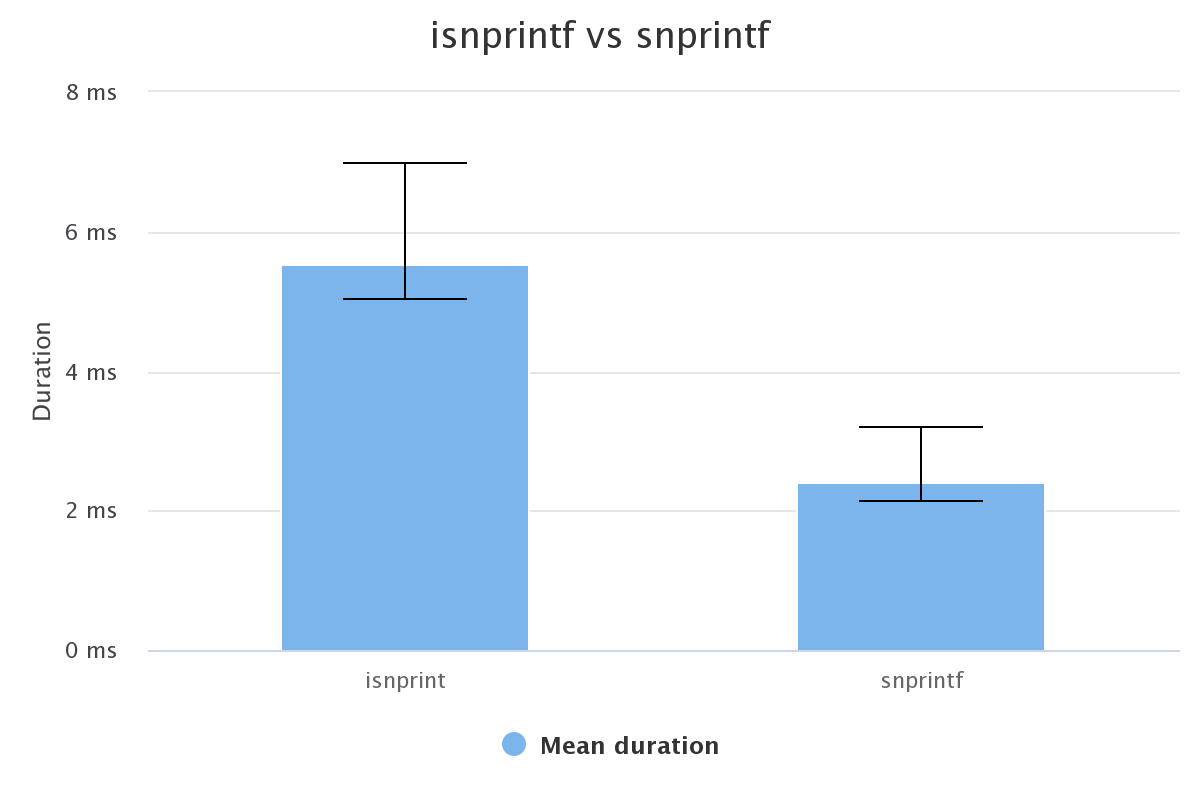
| function | real min (ms) | real max (ms) | real mean (ms) |
| isnprintf | 5.021 | 6.968 | 5.536 |
| snprintf | 2.123 | 3.187 | 2.408 |
As you can see, our implementation is about two times slower than the standard implementation in libc. So, it might be interesting to use the standard implementation instead of our own.
Unfortunately, we can define and use some custom formatters in our own implementation that are not trivially compatible with the standard implementation.
In conclusion, this is an interesting idea to improve the speed of lib-common, but it needs some rework in order to replace our own implementation.
IOP packing/unpacking
If you have read one of our previous articles, you already know what IOP is.
Long story short, and for what matters here, we use it as a serialization library. Since it is widely used in our products, we also decided to benchmark serialization and deserialization in binary, JSON, and YAML.
The purpose of this benchmark was not really to compare the performances of packing and unpacking with other implementations, but more for non-regression or comparison between JSON and YAML (indeed, as we could have expected, binary packing and unpacking is a lot faster – it is what is used for communication between daemons).
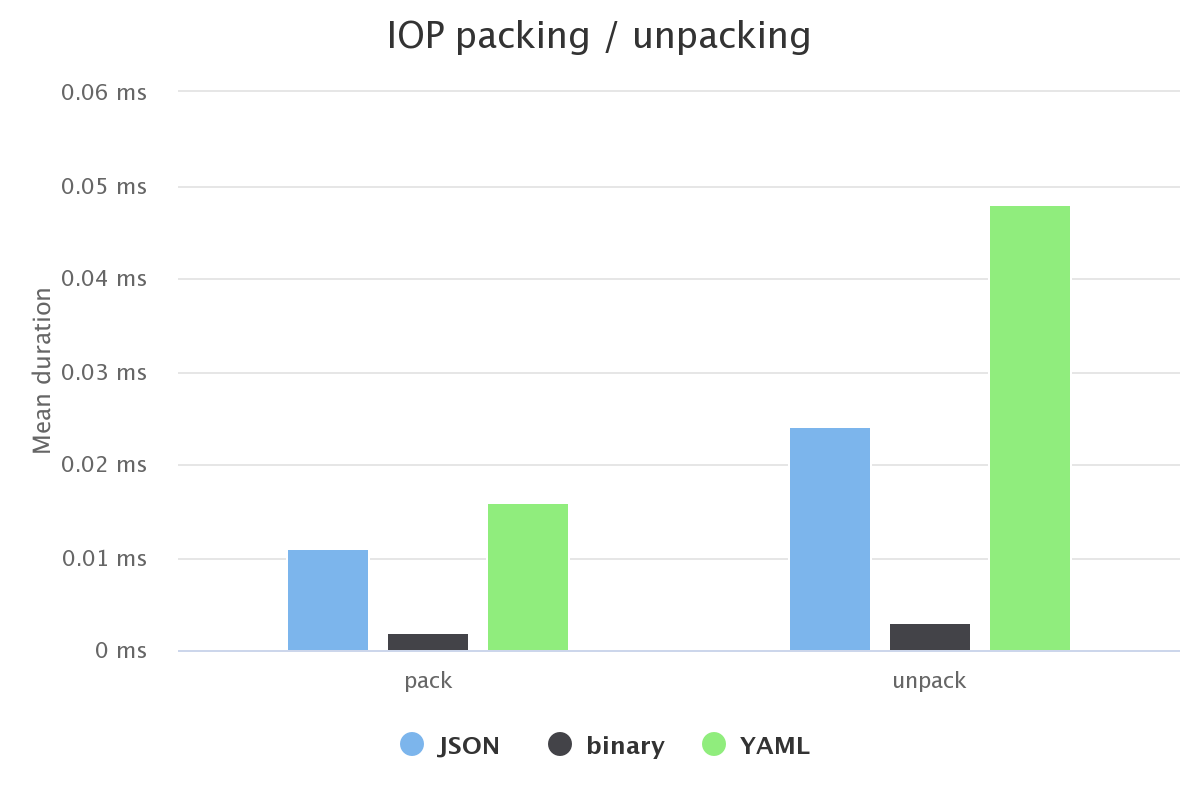
| function | real min (ms) | real max (ms) | real mean (ms) |
| JSON pack | 0.01 | 0.15 | 0.011 |
| JSON unpack | 0.018 | 0.192 | 0.024 |
| binary pack | 0.002 | 0.119 | 0.002 |
| binary unpack | 0.003 | 0.089 | 0.003 |
| YAML pack | 0.011 | 1.339 | 0.016 |
| YAML unpack | 0.033 | 0.328 | 0.048 |
We can see that unpacking costs more than packing, which seems normal, and that YAML unpacking seems particularly costly. This is an interesting point to keep in mind for optimization.
Bithack
The speed of lib-common is partly due to the optimization of low-level functions. One of these functions is membitcount which counts the number of bits set in a buffer.
We have four different implementations:
- membitcount_naive which does the sum of a naive bitcount on each byte of the buffer.
- membitcount_c which takes into account multiple bytes at once when doing the bitcount of the buffer.
- membitcount_ssse3 which uses the SSSE3 processor instruction set.
- membitcount_popcnt which uses the popcnt processor instruction.
The purpose of this benchmark is to check if the optimized implementations have a real impact on performance, or if we can keep a more naive implementation that is more readable and maintainable.
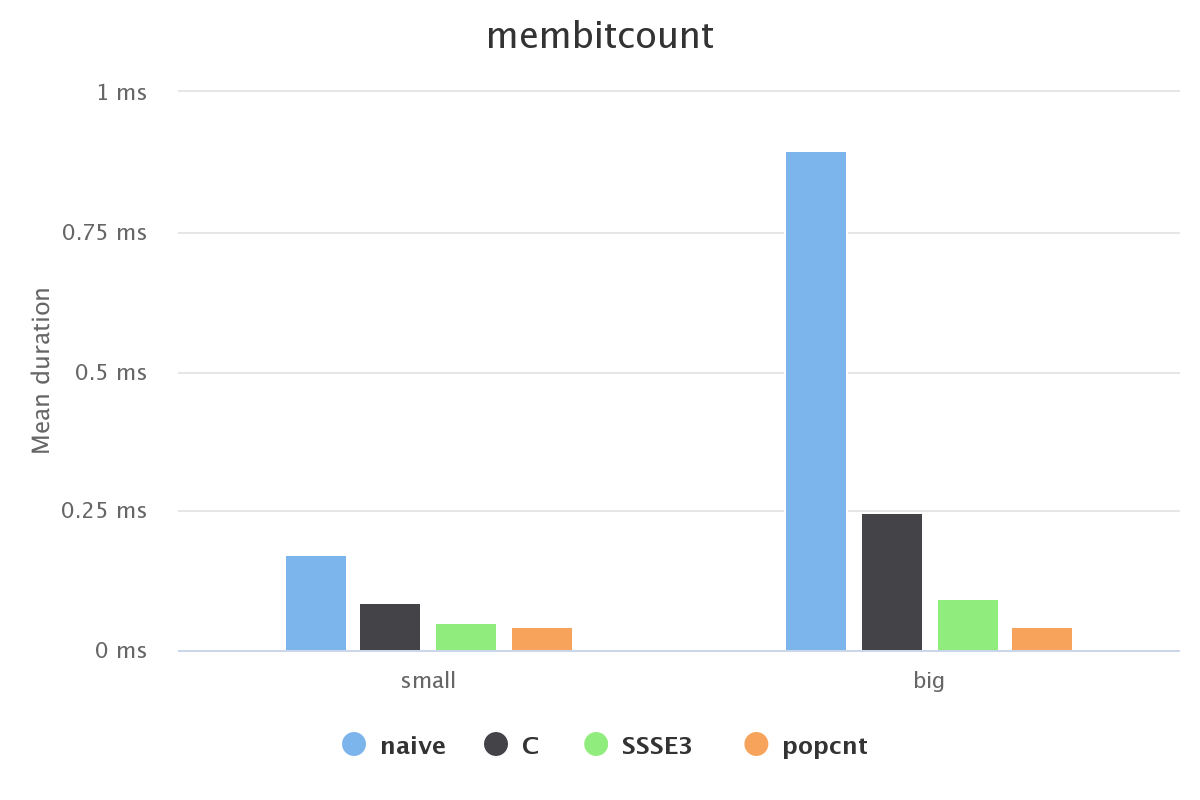
| Small | real min (ms) | real max (ms) | real mean (ms) |
| membitcount naive | 0.135 | 1.575 | 0.173 |
| membitcount c | 0.076 | 0.379 | 0.086 |
| membitcount ssse3 | 0.044 | 0.161 | 0.051 |
| membitcount popcnt | 0.038 | 0.11 | 0.044 |
| Big | real min (ms) | real max (ms) | real mean (ms) |
| membitcount naive | 0.721 | 11.999 | 0.896 |
| membitcount c | 0.215 | 12.882 | 0.248 |
| membitcount ssse3 | 0.078 | 0.23 | 0.092 |
| membitcount popcnt | 0.037 | 0.114 | 0.044 |
There are some real differences between the four different implementations, so the optimizations are legitimate. membitcount_popcnt is the fastest one, and it is the one actually used when available.
Spinlocks/Mutexes
Recently, there were some discussions about the use of spinlocks in the user space. In lib-common, we use some spinlocks in thread jobs.
The purpose of this benchmark is to check if replacing the spinlocks by mutexes has an impact on the performance of thread jobs.
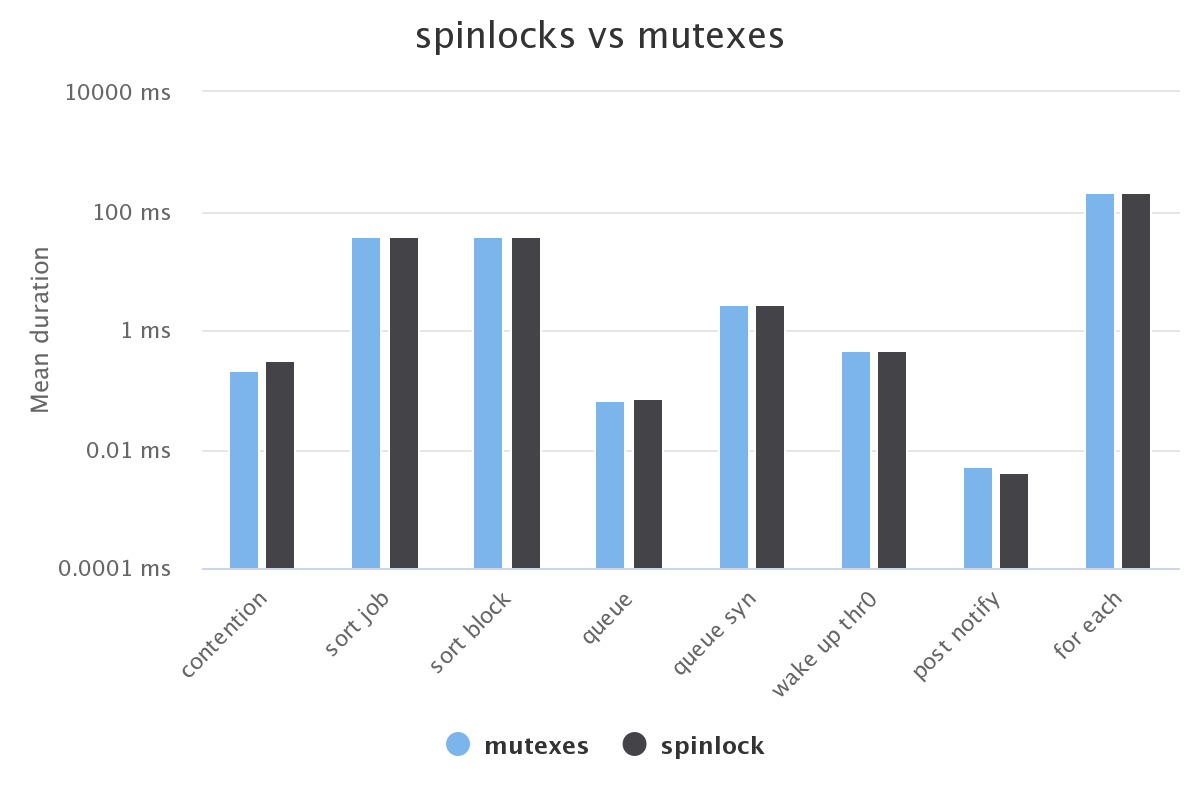
| thrjobs test | real min Mutexes (ms) | real min Spinlock (ms) | real max Mutexes (ms) | real max Spinlock (ms) | real mean Mutexes (ms) | real mean Spinlock (ms) |
| contention | 0.165 | 0.189 | 0.427 | 1.712 | 0.211 | 0.32 |
| sort job | 26.987 | 26.885 | 93.645 | 79.923 | 38.372 | 36.968 |
| sort block | 27.027 | 26.943 | 88.772 | 109.533 | 36.849 | 38.277 |
| queue | 0.039 | 0.04 | 2.139 | 4.068 | 0.067 | 0.074 |
| queue syn | 0.725 | 1.289 | 8.968 | 4.889 | 2.737 | 2.726 |
| wake up thr0 | 0.4 | 0.394 | 0.662 | 0.755 | 0.47 | 0.461 |
| post notify | 0.003 | 0.003 | 0.06 | 0.017 | 0.005 | 0.004 |
| for each | 195.948 | 182.7 | 224 | 224.167 | 210.577 | 209.49 |
The results are not conclusive. We see no visible impacts of switching from spinlocks to mutexes in the benchmark.
This might be because:
- There are no real macro differences when switching from spinlocks to mutexes.
- The differences are masked by the background noises of the benchmarks, they are not properly designed to test the modification.
Conclusion
Over this hackathon, we developed a new benchmark library, zbenchmark, that is easy to use and standardizes the output of the different benchmarks.
We also adapted and wrote some benchmarks to find future optimizations and avoid regressions.
Although there is still a lot of things to do (write new benchmarks, compare with standard implementations, find optimizations), the work done during this hackathon is promising.