
Middleware (or how do our processes speak to one-another)
About multi-process programming
In modern software engineering, you quickly reach the point where one process cannot handle all the tasks by itself. For performance, maintainability or reliability reasons you do have to write multi-process programs. One can also reach the point where he wants its softwares to speak to each-other. This situation raises the question: how will my processes “talk” to each other?
If you already have written such programs in C, you are probably familiar with the network sockets concept. Those are handy (at least compared to dealing with the TCP/IP layer yourself): it offers an abstraction layer and lets you have endpoints for sending and receiving data from a process to another. But quickly some issues arise:
- How to handle many-to-many communications?
- How to scale the solution?
- How to have a clean code that doesn’t have to handle many direct connections and painful scenarios like disconnection/re-connection?
- How can I handle safely all the corner cases with blocking/non-blocking reads/writes?
Almost every developer or every company has its own way to answer those questions, with the development of libraries responsible of communications between processes.
Of course, we do have our own solution too 🙂
So let’s take a look on what we call MiddleWare, our abstraction layer to handle communication between our processes and software instances.
What is MiddleWare ?
At Intersec, the sockets were quickly replaced by a first abstraction layer called ichannels. These channels basically simplify the creation of sockets, but we still deal with a point-to-point communication. So we started the development of MiddleWare, inspired by the works of iMatix on ØMQ.
First, let see how things were done before Middleware:
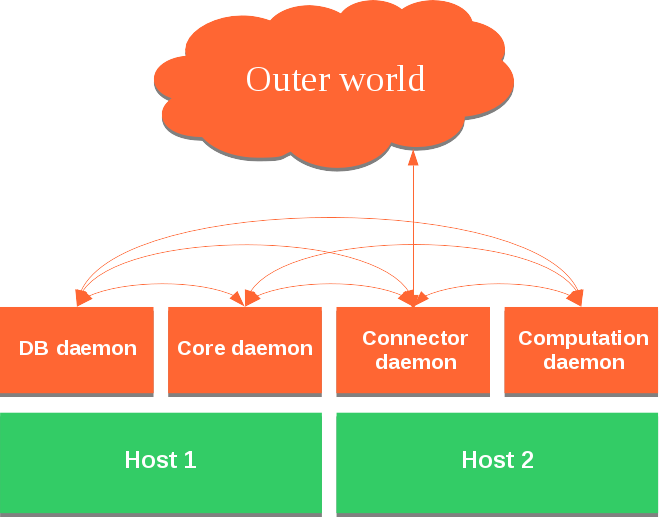
As you can see, every daemon or process had to open a direct connection to the other daemon he wanted to talk to, which leads to the issues described above.
Now, after the introduction of our MiddleWare layer:
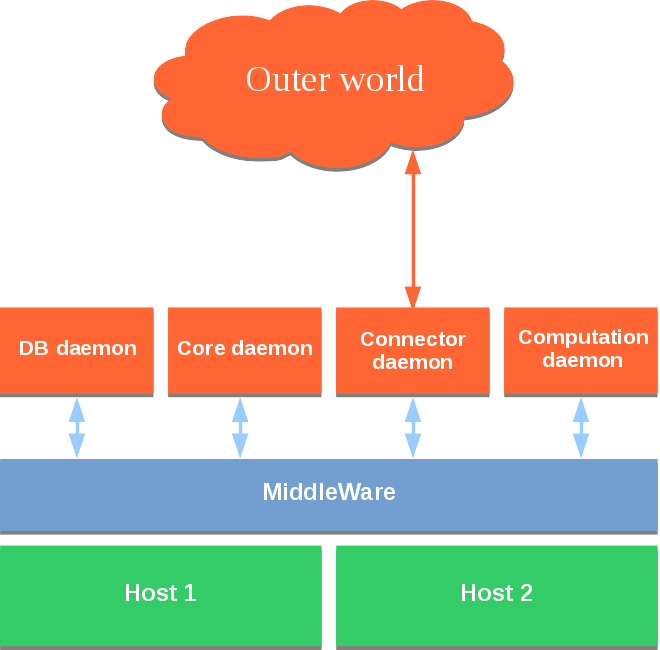
So what MiddleWare is about? MiddleWare offers an abstraction layer for developers. With it, no need to manage connections and handle scenarios such as disconnection/re-connection anymore. We now communicate to services or roles, not to processes nor daemons.
MiddleWare is in charge of finding where the receiver is located and routing the message accordingly.
This solves many of the problems we were talking about earlier: the code of a daemon focuses on the applicative part, not on the infrastructure / network management part. It is now possible to have many-to-many communications (sending a message to N daemons implementing the same role) and the solution is scalable (no need to create multiple direct connections when adding a new service).
Services vs roles
MiddleWare is able to do service routing and/or role routing. A service is basically a process, the user can specify a host identifier and an instance identifier to get a channel to a specific instance of a service.
Processes can also expose roles: a role is a contract that associates a
name with a duty and an interface.
Example: "DB:master" can be a role of the master of the database,
the one which can write in it, whereas "DB:slave" can be a role
for a slave of the database, which has read-only replicate of it.
One can also imagine a "User-list:listener" for example,
which allows to register a callback for any user-list update.
Roles dissociate the processes from the purpose and allow extensibility of the software by allowing run-time additions of new roles in existing processes. Roles can be associated to a constraint (for example “unique” in cluster/site).
Those roles can also be attached to a module, as described in one of our previous post. As module can be easily rearranged, this adds another layer of abstraction between the code and the actual topology of the software.
Some examples from the API
How does an API for such a feature look like?
As described above, one of the main ideas of MiddleWare is to ease inter-processes communication handling, and let the developer focus on the applicative part of what he is doing. So it’s important to have very few steps to use the “basic” features: create a role if needed, create a channel and use it and handle replies.
So first of all, let’s take a look at the creation of a channel:
mw_channel_t *chan = mw_new_channel_to_service(product__db, -1, -1, false);
And here you are, no need to do more: no connection management, no need to
look for the location of the service and the right network address in the
product configuration. A simple function call give you a
mw_channel_t pointer you can use to send messages.
The first argument is what we call a service at Intersec
(as said above, it is basically a process). Here we just want to have a
channel to our DB service. The second and third arguments indicate an host
identifier and an instance identifier, if we want to target a specific
instance of this service. Here, we just want a channel that targets
all the available instances of the DB service by specifying -1
as both host and instance ids. Finally, the last argument indicates whether
a direct connection is needed or not, but we will come back to this later.
Now let see some roles. Processes can register/unregister a role with that kind of API:
mw_register_role("db:master");
mw_unregister_role("db:master");
Pretty simple, isn’t it? All you need to do is give a name to your role. If we want to use a more complex role, with a unique in cluster constraint, we do have another function to do so:
mw_register_unique_role("db:master", role_cb);
The only difference is the need of a callback, which takes as arguments
the name of the role and an enum value. This enum represents the status of
the role. The callback will be called when the role is granted to a process
by MiddleWare: the new owner get a MW_ROLE_OWNER status in its
callback, the others get the MW_ROLE_TAKEN value.
On the client side, if you want to declare your role, all you have to do is:
mw_channel_t *chan = mw_new_channel_to_role("db:master", false);
And chan can now be used to send messages to our process which registered
the "db:master" role.
How does this (wonderful) functionality work?
The key of MiddleWare is its routing tables. But to understand how it works, I need to introduce to you another concept of our product at Intersec: the master-process. No doubt it will ring a bell, as it is a common design pattern.
In our product, a single process is responsible for launching every sub-process and for monitoring them. This process is called the master process. It does not do much, but our products could not work without it. It detects when one of its child goes down and relaunch it if needed. It also handles communications to other software instances.
Now that you know what a master is in our Intersec environment, let’s go back to MiddleWare and its routing tables.
By default, the routing is done by our master process: every message is transmitted to the master which forwards it to the right host and then the right process.
The master maintains routing tables in order to be resilient to network connectivity issues. Those routing tables are built using a path-vector-like algorithm.
So let’s take a look to another picture which show the communication with more details:
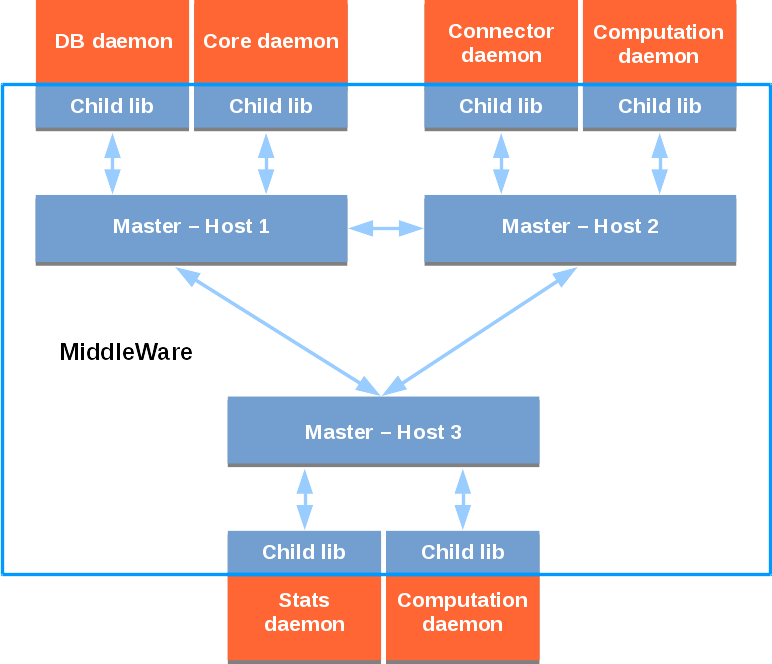
As we can see, MiddleWare opens connections between every master processes and their childs. There are also connections between each master. From the developer’s standpoint, this is completely transparent. One can ask for a channel from the Core daemon to the Connector one, or a channel between the two Computation daemons for example, and then start to send/receive messages on these channels. MiddleWare will route these messages from the child lib to the master on the same host, then to the master on the receiving host, to finally transfer it to the destination process.
In case you expect a large amount of data to go through a channel, it is still possible to ask for a direct connection to a process during the creation of that channel. MiddleWare will still handle all the connection management complexity and from that point, everything will work exactly the same. Note that in our implementation we never have the guarantee that a message will go through a direct link, as MiddleWare will still route the queries throught the master if the direct link is not ready yet. Moreover, every communication from a service to another will use the direct link as soon as it exists.
Tradeoffs
Having such a layer in a software does not come without some drawbacks. The use of MiddleWare creates an overhead introduced by the abstraction cost: the routing table creation adds a bit of traffic each time a process starts or stop, or when roles are registered or unregistered.
As start-up and shutdown are not critical parts of the execution for us, it is fine to have a small overhead here. In the same way, roles registrations are not frequent, it is not an issue to add some operations during this step.
Finally, high traffic may put some load on our master process that must route the messages. Not a big issue on that one too, as our master does not do much beside message routing. The main responsibility of this process is to monitor its children, no complex calculation or time-consuming operations here. Moreover, if an heavy traffic is expected between two daemons, it is a good practice to ask for a direct link. This decreases the load on the master and therefore the risk of impacting MiddleWare.