
C Modules
We do write complex software, and like everyone doing so, we need a way to structure our source code. Our choice was to go modular. A module is a singleton that defines a feature or a set of related feature and exposes some APIs in order for other modules to access these features. Everything else, including the details of the implementation, is private. Examples of modules are the RPC layer, the threading library, the query engine of a database, the authentication engine, … Then, we can compose the various daemons of our application by including the corresponding modules and their dependencies.
Most modules maintain an internal state and as a consequence they
have to be initialized and deinitialized at some point in the lifetime
of the program. An internal rule at Intersec is to name the constructor
{module}_initialize() and the destructor
{module}_shutdown().
Once defined, these functions have to be called and this is where
everything become complicated when your program has tens of modules with
complex dependencies between them.
The automated approach
A first approach can be to have everything done automatically. For
this, we do rely on non-standard C features. For example, with
GCC those functions can be made to be called automatically.
With GCC, we can use the attributes constructor
and destructor to have those functions called at the
initialization and the termination of the program:
__attribute__((constructor))
static void my_module_initialize(void)
{
/* module initialization code */
}
__attribute__((destructor))
static void my_module_shutdown(void)
{
/* module deinitialization code */
}
This approach ensures the constructor/destructor is called once and only once during the execution of the program. However, it also have some drawbacks. The main one being the fact we have no real control on the execution order of the constructors/destructors of the various modules. As a consequence, if a module A uses module B in its constructor, we cannot guarantee that B will have already been initialized when the constructor of A is called.
Another drawback is that this approach relies on the fact the linker
won’t evict the module at link time. By default, the linker works with a
granularity of the compilation unit: if no function of a compilation
unit is explicitly called by the program or by other functions
explicitly called by the program, then it is entirely evicted at link
time. So if a module has a constructor that has side effects and is
referenced by no other module (for example a watchdog module could be in
that situation), it may be silently evicted at link time, leaving your
program without some features. This can be worked around using some
special link options (--whole-archive) but this has
drawbacks too since you may generate bigger binaries containing code you
really don’t need… and calling the initializer of module you don’t care
about.
Ooh, and by the way, this approach cannot work if your module requires some parameters to be provided.
The manual approach
So, if we cannot use magics to initialize our modules, let’s do this
by hand. Instead of creating static functions with attributes, the
{module}_initialize and {module}_shutdown
become part of the API of the module. As a consequence, they must be
explicitly called at some point. Let consider an example program that
has two modules, one that handles the interaction with the user, one for
the administration:
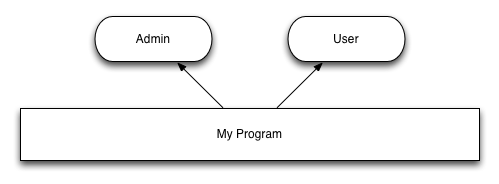
For that program, we would have functions like the following one to handle the intialization/deinitialization of the program:
static void my_program_initialize(void)
{
user_initialize();
admin_initalize();
}
static void my_program_shutdown(void)
{
admin_shutdown();
user_shutdown();
}
int main(int argc, char *argv[])
{
return daemon_main(argc, argv, &my_program_initialize, &my_program_shutdown);
}
The modules are independent, so the initialization/deinitialization order
is unimportant. However, let’s consider that the user module
depends on the authentication module:
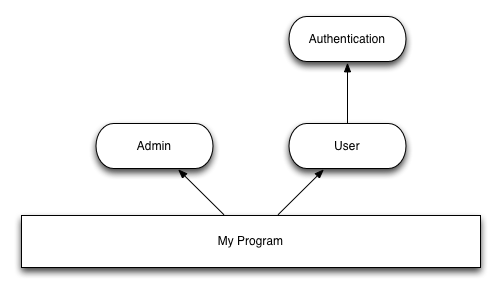
In that new setup, we do have a dependence from user on
authentication. As a consequence, we must make sure that
authentication is loading before user
and unloaded after user. This produces the following
initialization code:
static void my_program_initialize(void)
{
authentication_initialize();
user_initialize();
admin_initalize();
}
static void my_program_shutdown(void)
{
admin_shutdown();
user_shutdown();
authentication_shutdown();
}
This may looks simple, three modules to load in the right order, but
let’s suppose you have tens of modules to load that way, this starts to
become a big mess. Moreover, the fact my_program has to know
about the internal dependences of user and admin,
the two modules it exposes, breaks the “private implementation” rule:
the fact user depends on authentication is a
detail of implementation of the user module.
As a consequence, instead of letting my_program
load authentication, this should be done directly
by user. This can be done by calling the constructor/destructor
of authentication directly in user‘s ones:
void user_initialize(void)
{
authentication_initialize();
/* user initialization code */
}
void user_shutdown(void)
{
/* user deinitialization code */
authentication_shutdown();
}
static void my_program_initialize(void)
{
user_initialize();
admin_initialize();
}
static void my_program_shutdown(void)
{
admin_shutdown();
user_shutdown();
}
This looks much better. But in practice there are modules that are
actually needed by several other modules. Let’s improve our example by
supposing that both user and admin use a common
database module that handle the persistency and the access
to the data:
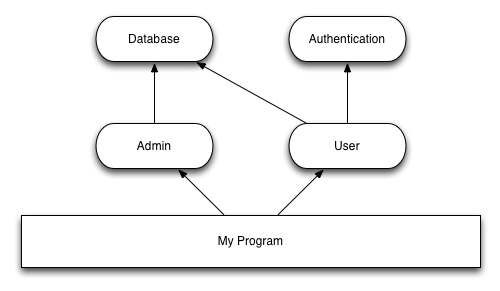
If we use the exact same approach as before, then the
database_initialize() function will be called twice: once by
user_initialize(), once by admin_initialize().
In order to fix this, we must add some guards within the module:
the initialization must only happen the first time
database_initialize() is called and shut down
the very last time database_shutdown() is called.
This is nothing more than applying a reference counting approach
to our modules:
static int database_refcnt_g;
void database_initialize(void)
{
if (database_refcnt_g++) {
return;
}
/* database dependences initialization */
/* database initialization code */
}
void database_shutdown(void)
{
if (--database_refcnt_g) {
return;
}
/* database deinitialization code */
/* database dependences deinitialization */
}
That’s it. We do have a pattern for properly and safely
initializing/shutting done modules. This requires 10 lines of
boilerplate code per module (including the declaration of the
{module}_initialize() and {module}_shutdown()
in the header file). The average size of a module is between a few
hundred and a few thousands of lines of code. 10 lines is an acceptable
overhead.
The declarative approach
So we are quite happy with our manual approach. With just a few coding conventions we can build a modular application with good properties. However, coding conventions are often not constraining enough to guarantee this will work everywhere.
Moreover, our modules actually need more than just a constructor and a destructor. Modules often respond to events such as the installation of a new configuration, the reception of a termination request, … As a consequence, the program has to propagate this kind of events to all interested modules. Unfortunately, we cannot easily rely on modules to propagate those kind of messages to their dependences: in case a module is the dependence of several other modules, it would receive the message multiple times. While we could solve this kind of issue using a simple refcounting for the constructor and destructor, this won’t work for the message handlers: messages can be received multiple times by the program and each module must receive once and only once each instance of the message.
As a consequence, the program has to call the handler of the various modules by hand, breaking the “private implementation” rule:
static void my_program_on_term(int signo)
{
database_on_term(signo);
authentication_on_term(signo);
user_on_term(signo);
admin_on_term(signo);
}
As a consequence, we built a library to reinforce the sturcture of a module. That library mostly maintains a module registry. That registry is an oriented graph of modules, each edge represents a dependence from a module to another. Additionally a state is associated to each module. That state indicates if the module has been initialized and handle the refcounting so that the module is shut down if it’s not needed anymore.
The library defines a standard way to declare and define a module. The initializer and shutdown methods don’t have to be public anymore, only the module has to:
/* Declaration of the user module in a header file */
MODULE(user);
The definitition of the module is done in a declarative fashion:
/* Definition of a module in a source file */
static int user_initialize(void *arg)
{
/* user initialization code, returns -1 in case of error */
return 0;
}
static int user_shutdown(void)
{
/* user deinitialization code, returns -1 in case of error */
return 0;
}
/* Module registration */
MODULE_BEGIN(user)
MODULE_DEPENDS_ON(database);
MODULE_DEPENDS_ON(authentication);
MODULE_END();
In this code, there only 3 lines of boilerplate per module (most of the
logic being moved to the library). With this approach our
my_program will looks like:
static void my_program_initialize(void)
{
MODULE_REQUIRE(user);
MODULE_REQUIRE(admin);
}
static void my_program_shutdown(void)
{
MODULE_RELEASE(admin);
MODULE_RELEASE(user);
}
The MODULE_BEGIN macro actually hides the use of an
__attribute__((constructor))
attribute that registers the module against the module-handling
library. The library itself is written in a such a way that modules can
be registered before the actual initialization of the library. The
module initialization method receives a pointer to a parameter that can
be specified in the program using MODULE_PROVIDE(module_name, value)
.
In order to be able to respond to events, the library defines the notion of methods. A method is an object that can be implemented by modules. Calling that method will call the implementations from all interested modules in the right order. Each method specifies if it should traverse the graph of modules by calling the implementation of the dependence before or after the implementation of the module.
/* Declaring the on_term method in a header */
MODULE_METHOD_DECLARE(INT, DEPS_BEFORE, on_term);
/* Implementing the method in a module */
static void admin_on_term(int signo)
{
...
}
...
/* Module registration */
MODULE_BEGIN(admin)
MODULE_DEPENDS_ON(database);
MODULE_IMPLEMENTS_INT(on_term, &admin_on_term);
MODULE_END();
/* Calling the method */
static void my_program_on_term(int signo)
{
MODULE_METHOD_RUN_INT(on_term, signo);
}
As a consequence, my_program doesn’t even have to send the
method of the modules it manually manages (user and
admin), all the loaded module that implement the
on_term method will receive that method when
my_program_on_term
is called. In addition to avoiding the leak of each module’s internals,
this approach avoids forgetting to add the call for one specific module
in the program.
Conclusion
Having modules done that way makes writing daemons simple.
In our codebase, the main() function of a daemon looks like:
int main(int argc, char *argv[])
{
return daemon_main(argc, argv, &MODULE(user), &MODULE(admin));
}
We pass pointers to the modules and the daemon library
(which is not a module) load them when everything is ready to be
started. We do write less administrative code with a improved
maintainability, and not too much hidden magic.