
In the third post of the memory series, we briefly explained locality and why it is an important principle to keep in mind while developing a memory-intensive program. This new post is going to be more concrete and explains what actually happens behind the scene in a very simple example.
This post is a follow-up to a recent interview with a (brilliant) candidate1. As a subsidiary question, we resented him with the following two structure definitions:
|
|
The question was: what is the difference between
these two structures, what are the pros and the cons of both of them?
For the remaining of the article we will suppose we are working on an
x86_64 architecture.
By coincidence, an intern asked more or less at the same time why we were
using bar_t-like structures in our custom database engine.
Pointer vs Array
So, the first expected remark is that here, we have the difference between
a pointer (foo_t) and an array (bar_t).
In C, a pointer is a variable that stores the memory address of the
data it references. In our case it is a 64 bits variable. So
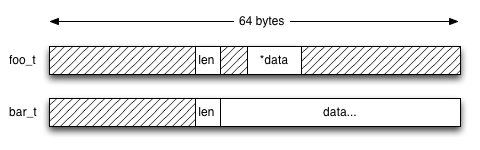
foo_t is composed of len that is a 4 bytes integer
and data that is a 8 bytes integer. Because
8 bytes integer have to be aligned on 8 bytes,
this has two consequences:
- the whole structure
foo_thas an alignement requirement of 8 bytes - the variable
datainfoo_thas an alignement requirement of 8 bytes
This causes, len to be aligned on 8 bytes, and data
to be placed on the next 8 bytes-aligned place, that is 4 bytes after
len, creating a hole of 4 bytes between the two variables.
The actual memory that stores the data is placed elsewhere, probably in a separate allocation.
The bar_t structure ends with a variable-length array of
characters. In C an array is a type that contains data. Developers are
often confused by the difference between an array and a pointer because
the language has an implicit cast from the array type to the pointer
one, just by taking the address of the beginning of the array (which has
the good property of making arrays and pointers accessible through the
same syntax data[i]).
void foo(void)
{
int buf[1024];
int *pbuf = buf;
typeof(buf) == int[1024];
sizeof(buf) == sizeof(int) * 1024;
typeof(pbuf) == int *;
sizeof(pbuf) == 8;
}
Another confusion comes from the fact the [] syntax can be
used in function argument types and in that case both syntaxes are equivalent
(however, the []
make it clear that we are talking about an array of values and not
about a single pointed object). This is indeed so confusing that
clang offers a dedicated warning for this
(-Wsizeof-array-argument).
static void bar(int *pbuf, int buf[], int bufsiz[1024],
int bufssiz[static 1024])
{
sizeof(pbuf) == 8;
sizeof(buf) == 8;
sizeof(bufsiz) == 8;
sizeof(bufssiz) == 8;
}
void foo(void)
{
int buf[1024];
bar(buf, buf, buf, buf);
}
So, in the case of our bar_t structure, our data
array just means that we want to able to access the memory that follows
len as a sequence of char (that is 1 byte).
An array has the alignment requirement of each individual object that it
contains, so our data array is aligned on 1 byte
which means it directly follows len in memory. bar_t
has no intrinsic overhead: its size is the size of its length plus the size of
the stored data.
This means our two structures have the following layouts in memory:

Allocations
In term of allocation, we already said that the data of the
foo_t structure can point anywhere in memory. Most of the time,
it comes from a separate allocation while the whole bar_t
structure can only result from a single allocation. This causes
foo_t to be more flexible: you can reallocate the data memory
without affecting the pointer to the foo_t structure. On the
other hand, the data array of the bar_t cannot be
reallocated without reallocating the whole bar_t structure,
potentially changing its pointer.
This causes the bar_t to be hard to embed by value in
another structure (it will only be possible to put it at the end of the
container structure) while foo_t can be placed anywhere.
Both structures can be pointed to by other structures/variables without
problem:
|
|
Because foo_t is larger that bar_t, it will
always consumes more memory than bar_t for the same length:
foo_t consumes 16 + len bytes while
bar_t consumes 4 + len bytes. Moreover, since
foo_t will most of the time require two allocations, each of
which has an overhead of at least 8 bytes (with the
glibc‘s ptmalloc2), this causes the actual memory
usage to be 16 + 2 * 8 + len for foo_t and
4 + 8 + len for bar_t. For a few large vectors,
this is not a problem, but if you want a lot of small ones, the overhead of
foo_t will be at least noticeable.
You can still allocate foo_t with a single allocation,
however this will make reallocation harder (since the pointed
data vector is not the allocated one and thus is not directly
reallocable). This will slightly reduce the overhead for foo_t
and improves the access performances (see next section). However the
improvements are worth only for small allocations, when bar_t
is already optimal.
struct foo_t *foo_alloc(int len)
{
struct foo_t *foo;
foo = malloc(sizeof(struct foo_t) + len);
foo->len = len;
foo->data = ((char *)foo) + sizeof(struct foo_t);
return foo;
}
struct bar_t *bar_alloc(int len)
{
struct bar_t *bar;
bar = malloc(sizeof(struct bar_t) + len);
bar->len = len;
return bar;
}
Locality
In order to better understand the performance’s implications, here is a
small code snippet that can apply to both foo_t and
bar_t. This simply gets the posth element
of the data or -1 if the position is out of range. For this, we read the
len member before dereferencing the data array.
int get_at(const struct foo_t *foo, int pos)
{
return pos >= foo->len ? -1 : foo->data[pos];
}
This produces the following assembly code (using clang -O2):
|
|
Both assembly codes start with the same sequence: the len
field is loaded ((%rdi)) and compared to the argument
(%esi). If the comparison shows the position is greater
(or equal) than len, we immediately go to the end of the function
and we return %eax in which -1 has been previously stored.
In order to read len the processor has filled a line of its
cache with the bytes surrounding the structure. Since a line of cache on
current x86_64
processors is 64 bytes-long, the nearby memory is also loaded in the
CPU, which gives on average 30 bytes of memory following the length.
This means that the line of cache looks like this:
At this point, in the case of foo_t we loaded the 4 bytes of
the length and the 8 bytes of the pointer to data as well as a
lot of garbage. In the case of a bar_t, we fetched the 4 bytes
of len and a few tens of bytes of the actual data.
In case foo_t used the single allocation mechanism described
above, a few tens of bytes of data would also be loaded, but
on average 12 bytes less than bar_t (because of the size of
the pointer and the hole in the structure). 12 of 64 bytes is a substantial
part of the line of cache.
The next step in the case of a structure foo_t, is to load
the pointer data (8(%rdi), which means the content 8
bytes after the address stored in %rdi) and stores the address in
%rcx, then to load the data placed at that pointer plus the
pos ((%rcx,%rax)) and move the value to
%eax (since this stores the return value of the function).
That particular instruction loads another line of cache.
In the case of the bar_t, the data array is in the
continuation of len, which means that the address from which the
result must be loaded is the address of the structure plus 4 (the size of
len) plus the position to fetch (4(%rdi,%rax)).
As a consequence, only a single instruction is required to load the value,
not two, and in case pos is small, the source of the move will
fall in the same line of cache as the one that was already fetched.
So, what’s the gain of bar_t here? In all cases, accessing
the content of foo_t
requires an indirection which result in an additional instruction to
load the address of the pointer. However, in most cases, this additional
instruction will have a very limited cost since the loaded pointer is
already in the same line of cache as len (most of the time at
least): loaded memory from a L1d cache costs only 4 CPU cycles.
Then, in both cases, the actual value is fetched. If the value is
already in cache, this will cost 4 CPU cycles, however if it must be
loaded from the main memory, this will cost more that 100 CPU cycles. In
the case of a foo_t, the data will (almost) never belong
to the same line of cache as the structure, as a consequence it is
highly probable that a new line will have to be fetched from the main
memory. In case of bar_t, if the pos is small, we
will hit the same line of cache as the already fetched one, if
pos is large, we will have to fetch a new line of cache.
As a consequence, the execution of the get_at function
on a foo_t
will cost one load from main memory, a load from L1d, and a second load
from main memory, which means more than 204 cycles. The same execution
on a bar_t will cost from 104 to 200
cycles, depending on the value of pos.
These estimations are the worst case scenarios, however if that
structure has been used recently, it is highly probable that the
associated memory is already loaded in one of the levels of cache,
reducing the latency. But caches are small, thus if you really want to
benefit from them, you will have to group the accesses to the same line
of caches together.
Conclusion
So, yes, using a bar_t-like structure is worth it, depending
on your use case. It will always be faster that the foo_t-like
structure, but the gain will probably not be noticeable if the stored
data spans on several lines of cache. That said, since
foo_t-like structures can easily be embedded by value in a
structure while bar_t-like structures will often have to be
accessed by pointer ((a linked-list of structures would be a good use case
for bar_t-like structures, since the linked-list entries must
be accessed by pointer
[↩]