
Web Speech API - Creating a web interface with 0 clicks
Context and purpose
This project was part of the 12th Intersec Hackathon (0x0C). We had 2 days (31 hours) to develop and present our project. Our team consisted of Yohann Balawender and Benoît Mariat.
The purpose of our project was to explore the Web Speech API and to use it in an Intersec product to send verbal commands that would replace the use of a mouse, even for complex actions.
Technology used
The Web Speech API makes it possible to integrate speech data into web applications. There are two parts:
The MDN website provides a good description of the API.
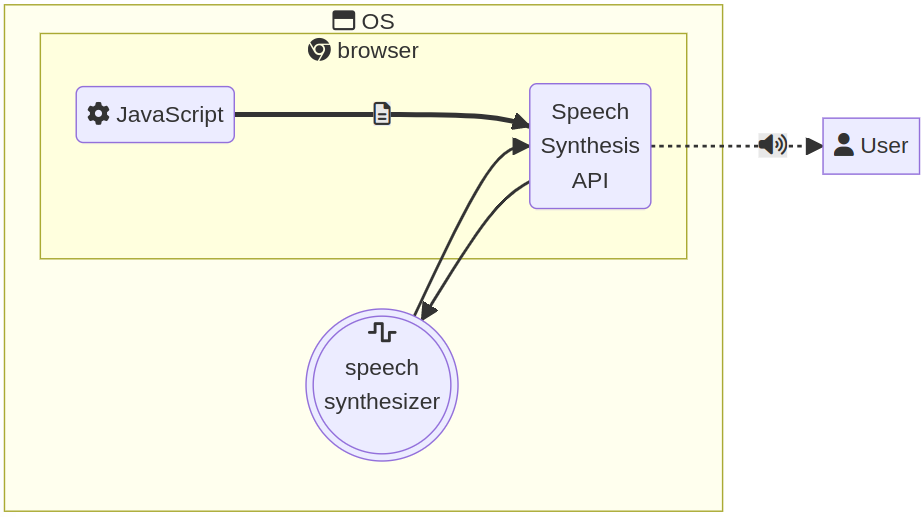
SpeechSynthesis
This API allows text to be read with a synthesized voice.
const utterance = new SpeechSynthesisUtterance('Hello!');
speechSynthesis.speak(utterance);
Unfortunately, our initial tests were a failure. We noticed that the following piece of code returns an empty array.
speechSynthesis.onvoiceschanged=() => {
console.log(speechSynthesis.getVoices());
}
It should display all available voices on the current device.
So we decided not to use this part of the API.
Later on, after the Hackathon, further investigation showed that we needed:
- To install speech synthesizer Voices on our computer
- To start Chromium with the experimental
--enable-speech-dispatcherflag
It worked after installing the open source speech synthesizer software
espeak
.
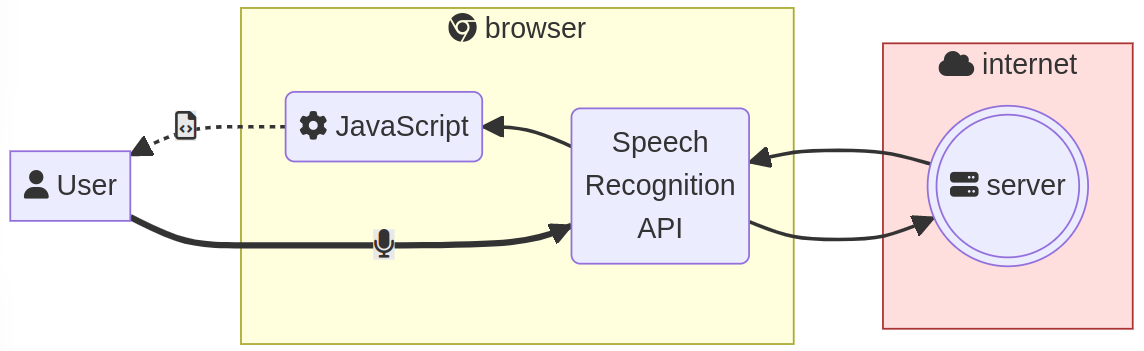
SpeechRecognition
This API recognizes the user’s voice and translates it into text.
It is quite easy to use, but it requires some parameters and has some disadvantages.
const recognition = new SpeechRecognition();
recognition.start();
Because the API is asynchronous, we should add methods to the instance in order to be notified of any change about progress, result or error. They behave like event listeners.
recognition.onresult = (event) => {
const text = event.results[0][0].transcript;
console.log('result: %s', text);
};
Settings
It is possible to configure speech recognition by setting some properties before starting.
const recognition = new SpeechRecognition();
recognition.lang = 'en-US';
recognition.start();
The lang property defines the language in which speech recognition is performed.
We observed that in English the confidence level was between 75%~80%, while in French (which is our native language) it was around 90%~95%.
So we decided to implement all commands in French.
recognition.lang = 'fr-FR';
To be a bit more confident we read 5 alternative results.
recognition.maxAlternatives = 5;
We decided not to listen to the user all the time but to start the recognition
process only when the user clicks on the icon or hits the ² key (which is
almost never used on AZERTY keyboards).
recognition.continuous = false;
window.addEventListener('keydown', (evt) => {
if (evt.key === `²`) {
recognition.start();
}
});
We also decided to wait only for the final result. But getting intermediate results (interim) enables the user to check the speech flow. And analyzing those results also allows to start speech recognition faster.
recognition.interimResults = false;
With our setting, the user has to start the recognition process manually. The result is available about 1s after a blank (no speech).
Compatibility issue
The biggest problem we faced was to find a browser in which we would be able to run the code.
Because the API is still in draft mode, some browsers have not implemented it yet. There is still no Firefox version that works with this API.
It also requires a remote server to run speech recognition. This is probably why Vivaldi and Brave give a “Network” error.
Fortunately, it works with Chromium with restrictions for security reasons: the application should run under the https protocol, and the user should allow the use of the microphone.
We did not find any settings to configure a different recognition server which would have been great for customers who are only on a local network and do not have access to the Internet. For customers who have a strong privacy policy and don’t want to connect to the Internet, this could be a big problem.
First usage
At this stage, we can use this technology to fill text forms. For example, in a conversation with a chatbot.
This chatbot can be used for many purposes in the product:
- Deep search website
- Answer simple questions about a result or an activity on the platform
- Suggest multiple choices based on the context
- Perform actions on user commands
So users don’t have to type their messages, they can simply dictate them, which is very convenient.
Understanding sentences
We chose to implement the execution of actions on user commands. On our product GeoSafe PWS, we can perform cool features, but even with basic use-cases, it takes a few clicks such as the creation of a zone. We could save up to 20 clicks with just 2 or 3 voice commands. The improvements and possibilities are huge, so we decided to go in that direction for our Hackathon.

First, we needed to understand the spoken sentence to turn it into a command.
There are 2 deprecated attributes in the recognition results:
These attributes should have a semantic interpretation on texts. But since they are deprecated, we cannot rely on them (and they are no longer filled by Chromium).
So, for this short project, we decided to build our own solution that would search for keywords in the sentences.
First we removed some words to simplify the sentence:
- Articles (such as “un”, “de”, “des”, “la”, …)
- Prepositions (such as “sur”, “avec”, “dans”, “pour”, …)
- Conjunctions (such as “et”, “ou”, …)
- Some keywords that we can use to build sentences (such as “ayant”)
This way, a sentence such as “créer une zone ayant pour nom foo” (“create a zone whith the name foo”) can be transformed into “créer zone nom foo” (“create zone name foo”).
Then we also removed the personal pronoun (“je”, “tu”, …) and the following word that we expected to be a verb. This transformation allows us to build sentences like “je veux afficher les zones” (which becomes “afficher zones”) or “tu peux centrer sur Paris” (which becomes “centrer Paris”).
With this method, it is very easy to keep only the important words, and translate them into “understandable machine-commands”.
The first word is considered as the key command.
To improve the ability to recognize the correct command and because the word
might be included in a real sentence, we accept many spelling variations of
the same word with similar pronunciations. For example, for the command
“create”, we accept "créer", "créé", "créée", but also "craie"
which is phonetically close.
We thought about using the Levenshtein distance (which compares the difference between 2 words), but we got good results without it, so we did not implement this solution.
Creating such a map also helped us add several words for the same
command, such as for "lister" (list) and "afficher" (display).
When a command is recognized, the rest of the sentence is read to find specific
keywords. For example, for the “create” command the syntax looks like
"create <what> [<nameKeyWord> <name>][<otherKeyWord> <values>]"
<what>can be “zone”, “message” or “alert” which are the objects we handled in this project. Each of them has its own attribute keywords.<nameKeyWord>which can be “nom” (name) or “nommé” (named) means that what follows is the name of the created object.<name>is a string of any number of words that are not keywords.<otherKeyWord>are other keywords depending on the created object.<value>are strings of any number of words that are not keywords.
Attributes can be said in any order or not said at all.
Executing commands
Once the command and all its options are built, we need to execute the operation.
For most commands, it was not possible to simply send a query to the server. This is because most of them are front-end actions or can fail during the process. We also wanted to make sure that if something went wrong during the creation phase (such as an invalid name), the user would be able to change it and complete the operation.
Our first step was to send the command in an event through a broadcast channel. And then in dedicated components to execute the right operations. But it became quite difficult to adapt the code and this was very time consuming. Moreover, things get more complex when multiple actions are required in a row.
Our second step was to create an automate that would execute simple operations, such as “click” on a DOM element or fill in a text input. Developing this automate was quite simple. And it was very easy to feed it with new entries to support complex components or complex actions on multiple pages.
In addition, if some of the values are wrong, the automate stops like a user who has entered a wrong name. The user keeps control of the creation process.
Results
The final result was quite impressive.
First, the recognition API is very efficient. It works correctly even in a noisy environment, but also for onomatopoeia like “plop” or “yop”. It only has some defaults with names like “Yohann” where it returns “Johan”, or “Orianne”. So we still need to check the result when we use it to fill in a name field. Sometimes it doesn’t really stop on its own. We had to stop it and force the recognition process.
Our transformation of sentences into commands was surprisingly very resilient. We tested it on several people who didn’t know the right keywords. And they were able to execute commands naturally. The ability to use complete sentences was a big advantage. It could be improved by adding new keywords for the same commands. For example, during the presentation, Rawad, who had never tested the application before, said “Je veux aller à Rueil Malmaison” (I want to go to Rueil Malmaison). However, “aller” was not implemented, but it could be added as another keyword for “center” like “centrer” and “voir”.
Performing complex operations was surprisingly easy; only a few keywords were needed. And even for a simple operation like navigating to another page, the user doesn’t have to look for the page name in the menu and click on it. After playing with the vocal commands for 2 days, I found it easier to say “navigate to XXX” than to look for the page name and click on it. So we can expect that if the application is fully speech-enabled, it will really change the user experience.
What’s next in the near future?
This project was great and fun because the voice-user interface is a rich subject. It requires multidisciplinary skills such as computer science, linguistics, and human factors psychology. But it is not realistic to imagine that it could be in production currently. Mainly because of the poor compatibility of the API (only few browsers support it and sometimes with particular options).
In the very first test we did with the embedded recognition service, the results were quite impressive. However, they vary from one language to another, as does the level of confidence we place in each of them. With different levels of trust, implementation can be different, costly, and hard to maintain over time.
We chose a simple algorithm that filters out keywords, but it cannot work with natural language and therefore has usability issues (if the user hesitates, doesn’t pronounce the right expected words or not in the right order, the action is not recognized and consequently fails).
To improve command recognition, we would use many natural language processing techniques involving machine learning (probably LSTM network), which requires special skills.
However, we can learn from this experience and prepare some improvements.
Usage
It makes sense to introduce the speech-recognition technology in cases where it enhances user experience. For example, it can be useful to fill in the content of a message or when long text is expected. It doesn’t matter if the browser support is poor, because it is just an enhancement.
Using it could also help improve the accessibility of the application.
The automate
The basis of the automate could be reused and improved for some other usages. For example, it could be used for integration tests or to perform actions on behalf of the user, such as in a tutorial.
Creating a smart bar
Similarly to voice commands, we can imagine having a common Smart Bar in the application. It would perform various actions, such as searching for items or executing commands. The user could receive feedback on the commands entered and how they were interpreted.
It could accept sentences that would be interpreted as commands. Just like speech recognition, sentences would need to be translated into commands.
So, developing such a component can greatly enhance the user experience and it will be easy to integrate it once the Web Speech API is ready.
Conclusion
Even though this project was more a proof of concept, and the technology is not yet fully mature, we see a lot of possibilities for features that can be developed now and will unleash their full power when speech recognition is ready for a bright and shiny future!