
Hackathon 0x0a - Deep stop-segments: when cellular location and image recognition encounter
Objective
Expertise in location data is at the core of Intersec technologies. Retrieving and exploiting such data from cellular networks helps us address use cases in various fields like public safety, location-based advertising or smart cities and territories.
When dealing with raw locations retrieved at an antenna level within these networks, a central challenge is to infer when a device is staying in the same area or when it is moving. What might seem simple when we think about GNSS trajectories (for example, based on GPS coordinates) is not that easy when we have to handle antenna-based locations.
The following map illustrates that point: the blue line links the successive locations retrieved from the cellular network, with grey circles showing the theoretical accuracy of these locations.
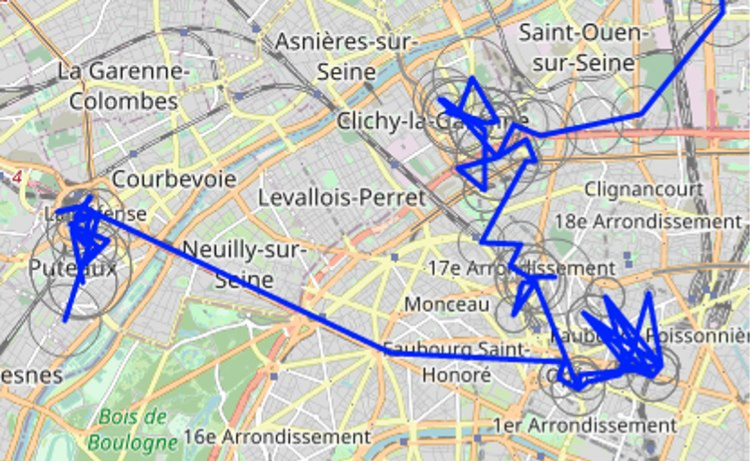
We clearly see how noisy this location data is, with a very jerky trajectory. We can infer visually some “stay areas” when we see bunches of points around the same place, but we understand that advanced algorithms are needed to automatically find periods of stay (“stops”) and of travel (“moves”).
Intersec owns a patent for such an algorithm, called “stop-segment”. We are currently working on improving it further, but what we wanted to test during this hackathon was a totally different approach, relying on image recognition.
The starting point of the idea is what we mentioned earlier in this post: when looking at trajectories on a map, we might have a sense of when the device is moving and when it is stationary. So, if a human eye can figure this out, would image recognition also be able to do it? We had two days to dig into this question.
Image recognition
Commonly used models in image recognition are convolutional neural networks (also referred to as “CNNs”). Introducing them in detail is outside the scope of this post, but interested readers might have a look at this introductive video or this more technical blog article , among others.
For the purpose of our post, let’s just see convolutional neural networks as huge mathematical formulae, relying on many parameters (possibly billions), that can take an image as input, and return a score indicating if this image contains a given object or not.
Specializing the model to be able to detect given types of objects is done through a process that we call “training”, and is based on already labeled images. In other words, if we want a neural network to detect if images show cats or not, we first have to feed it with many images, labeled as containing a cat or not. Based on such images, the model learns what a cat image is, by adapting its parameters until it is able to correctly classify images for which the answer is already known. Once that training phase is done, the model is able to classify new incoming and unlabeled images.
Building proper training data for such models is one of the main parts of the job of a machine learning engineer, as the model in itself is often accessible through dedicated libraries.
Training our model
Our goal was to use CNNs to be able to detect “stops” and “moves” in our trajectories. As mentioned above, such models need training data to “learn”: as powerful as these models are, they initially have no idea of what a stop or a move is. Thus, we had to feed our model with labeled images.
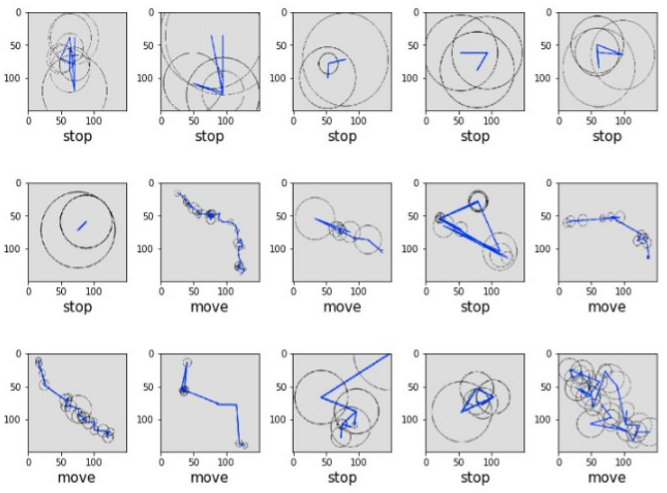
So, we had an enjoyable moment during the hackathon, generating trajectories on maps, screenshotting them and labeling each of them manually, ending up with 673 screenshots, labeled as “stops” and “moves”.
Let’s say a few words about these images:
- First and most importantly, our final objective is to split any trajectory into a sequence of stops and moves. So, the purpose of our model is NOT to look at images of already split stops and moves to see if it classifies them correctly; we want our approach to perform this split itself. The way we chose to work was to split our trajectories into 1-hour “subtrajectories”, and infer for each of them if this subtrajectory contained a move or not (for example, a 1-hour trajectory containing a 15-minute move will be labeled as “move”).
- Second, even if for a human, the underlying map might be important to infer the device’s mobility, it might introduce noise for the model, so we chose to only display the trajectory itself, without any map tile in the background.
Below are represented a few examples of labeled images, representing each 1 hour of data with at least 5 locations, along with their manually set label, indicating if this hour contains part of a move (“move”) or not (“stop”):
As explained above, our manually labeled data is used to train our CNN. Again, technical details are beyond the scope of this article, and we did not spend a lot of time tuning the parameters of our model during the hackathon. But for interested readers, let’s just mention that we used TensorFlow to build this CNN, with three Convolution+MaxPooling layers, before the flattening and final classification layers. This ended up with a network with millions of parameters, that performed the training in less than 10 seconds on Google GPU accessible through their “Colab” notebooks.
Results
Now that our CNN is trained on our manually labeled screenshots, it is able to classify unlabeled images into stops and moves. To evaluate how precise this inference is, we kept aside a part of our labeled dataset, that is independent from the images used to train the model. The idea is to let the model make its classifications on that part, and then compare them to the ground truth that was manually labeled.
Out of our 673 screenshots, 100 were kept to perform this evaluation: 39 stops and 61 moves.
Below are represented a few examples of labels inferred by the model: ground truth label is written under the image, with correct classifications in blue, errors in red. The table that follows presents the overall results of the model’s classification on our evaluation dataset.
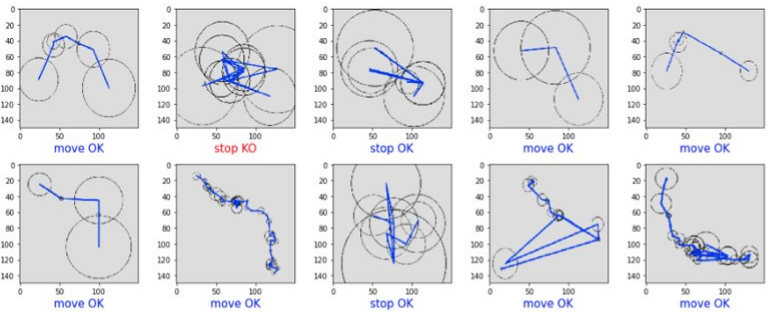
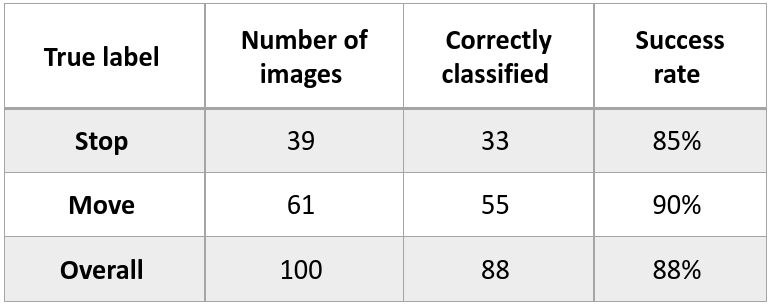
The reasons why the model fails at inferring the right label on erroneous cases is sometimes unclear, and again we missed time to investigate this very precisely, but the overall performance of almost 90% of correct labels is a decent result and proves that detecting stops and moves through image recognition is plausible.
Application to trajectory split
Now that we have at our disposal a classifier that showed reliable performance at inferring if 1-hour trajectories contain moves or not, let’s go back to our initial objective: split trajectories into stops and moves.
A basic approach could be to simply split our whole trajectory into 1-hour periods, and label each of them with our classifier. The granularity of the output would nevertheless be unsatisfying: a move of 15 minutes would lead to a whole hour detected as move. Even worse: a short move straddling two periods would lead to two consecutive hours labeled as move!
So, we need a finer-grained approach to be able to detect more precisely relatively short moves. Our approach consists in looking at 1-hour trajectories starting every 15 minutes. Doing so, each period of 15 minutes is covered by four distinct 1-hour trajectories, so ends up with 4 labels. The rule we apply is to consider that the 15-minute period is a move if and only if all covering periods are labeled as move. By applying this methodology, we accept to miss stops lasting less than one hour, but are able to narrow our move detection to periods of 15 minutes (and short moves are known to be more frequent than short stops).
Real life case
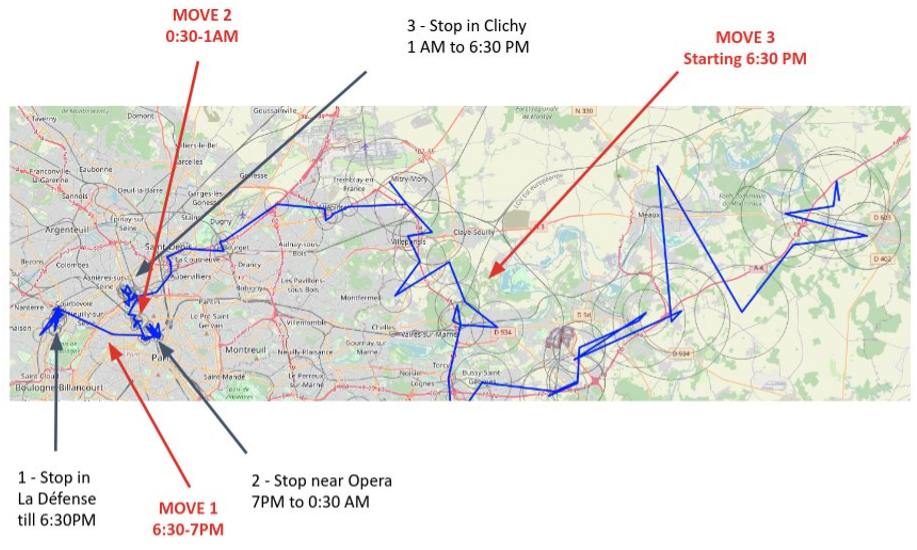
Let’s go back to the example shared in the introduction. We have at our disposal a bit more of 24 hours of location (from Day 1 - 5:00 PM to Day 2 - 7:15 PM). The ground truth mobility of the underlying device is as follows:
- Day 1, from 5:00 PM to 6:30 PM: stop near “La Défense”, business district located west of Paris
- From 6:30 PM to 7:00 PM: move to Opéra district in Paris (called “MOVE 1”)
- From 7:00 PM to Day 2 12:30 AM: stop in Opéra district
- From 12:30 AM to 1:00 AM: move towards Clichy, city located just north of Paris (called “MOVE 2”)
- From 1:00 AM to 6:30 PM: stop in Clichy
- From 6:30 PM: start of a move towards east (called “MOVE 3”)
These steps are pointed out on the map below:
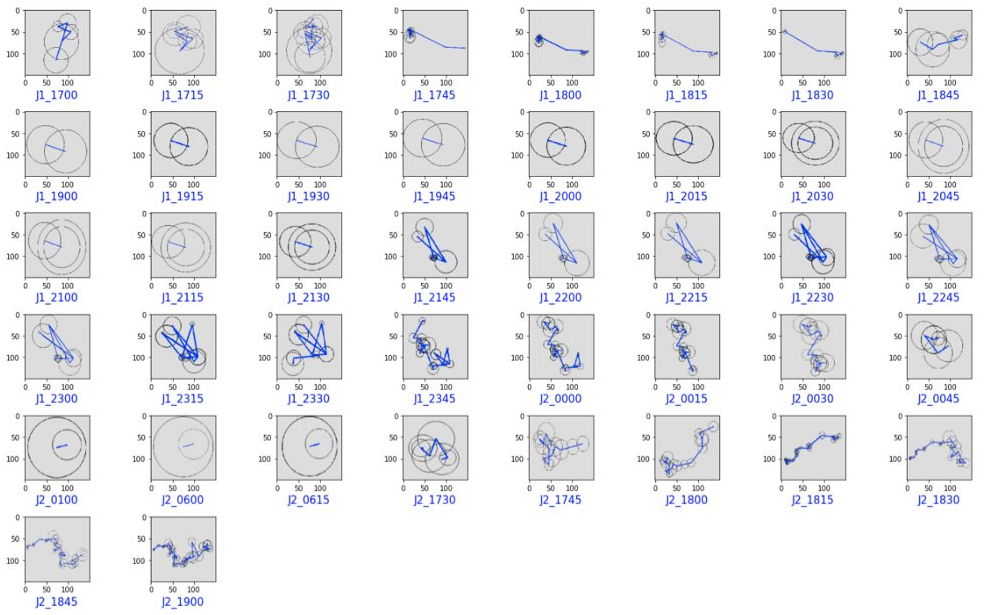
As explained, this trajectory is split into 1-hour trajectories starting every 15 minutes. Below are represented these “subtrajectories” as soon as they contain at least 5 locations. The label below refers to the starting time of the hour period (ex: J1_1815 means that we consider the 1-hour period starting at 6:15 PM on Day 1).
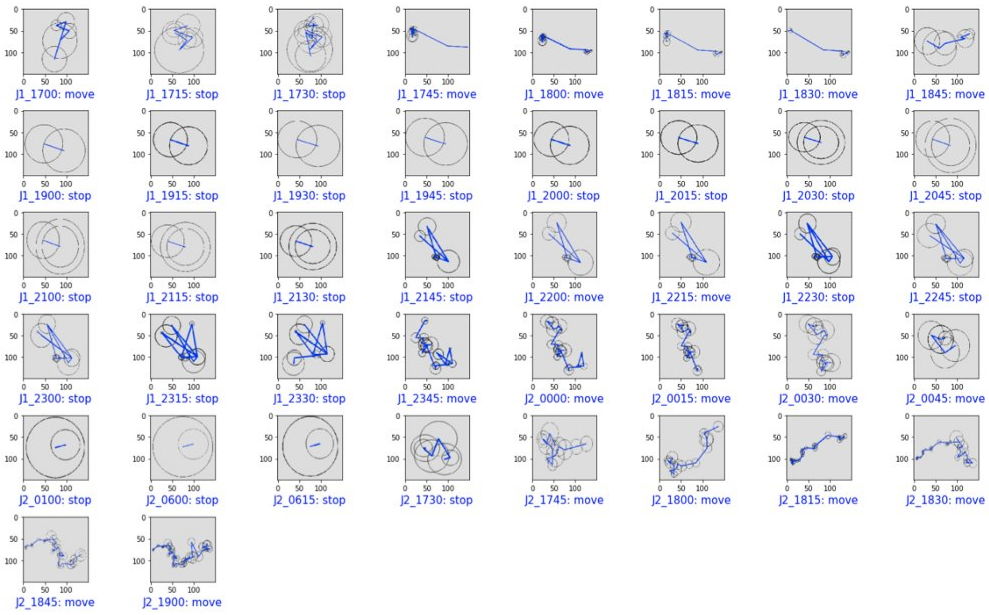
Then, we apply our classifier on all these periods, to end up with a “stop” or “move” label for each of them:
Finally, we apply the rule described above to end up with our final classification: we need four consecutive 1-hour trajectories labeled as moves for the 15-minute period covered by these four trajectories to be considered as a move (otherwise this is a stop). For example, 1-hour trajectories starting at 5:45 PM, 6:00 PM, 6:15 PM and 6:30 PM labeled as moves will mean that the 6:30 PM to 6:45 PM period will be finally flagged as move.
If we highlight in the above labels the periods that are the fourth move of four consecutive ones, displaying them in red, we end up with the result below. Consecutive periods in red are grouped into blocks.
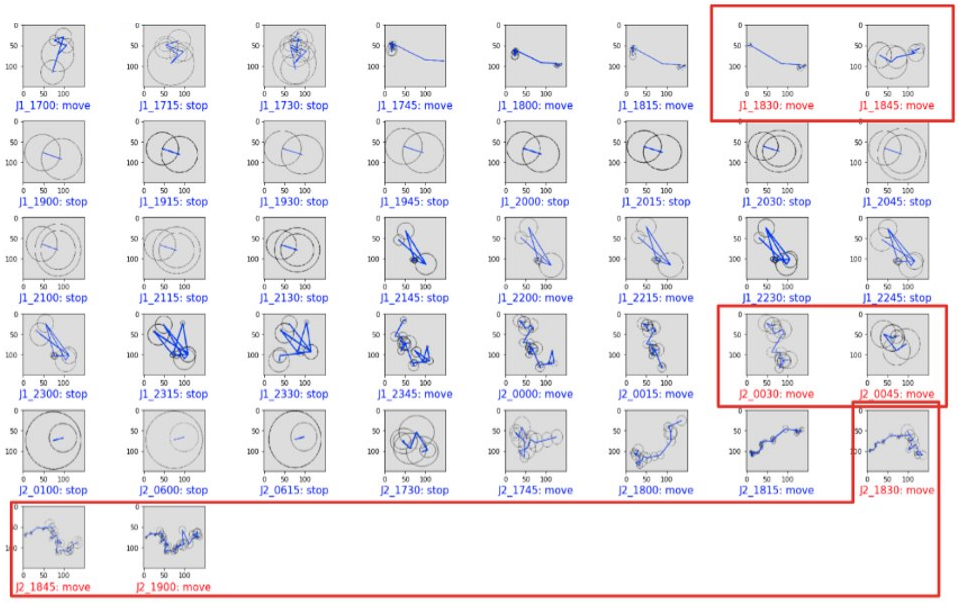
Can you feel it, the smell of success?
- Within the first block, periods are 15-minute ones starting respectively at 6:30 PM and 6:45 PM on day 1, so compose the 6:30 PM to 7:00 PM interval: exactly MOVE 1!
- Within the second one, 12:30 AM and 12:45 AM on day 2, so the 12:30 AM to 1:00 AM period: this is MOVE 2!
- Within the third one, 6:30 PM, 6:45 PM and 7:00 PM, composing the 6:30 PM to 7:15 PM period: we found MOVE 3!
- All other periods are stops, as in the ground truth described above
In the end, we managed to use image recognition to split this trajectory into stops and moves perfectly fitting the ground truth mobility behind the retrieved locations!
To sum up
Our goal for this hackathon was to test the idea that AI-based image recognition was able to detect periods of stops and moves in a noisy trajectory displayed on a map, as a human eye could do. We’re quite proud of having managed to prove it in less than two days! Thanks to our unitary CNN model, labeling 1-hour periods, and to the way we integrated it in a more extended methodology, allowing to split a trajectory of any length into sequences of stops and moves.
Of course, this approach should not be used at scale in industrialized solutions, as generating images would be a huge and consuming task, sometimes unnecessary when simple distances and time differences are enough to label a stop or move, and as some points were not looked at during our two-day hackathon (what if we have less that 5 points in an hour? Could we detect shorter stops and shorter moves simultaneously? Etc).
Anyway, this topic was a good opportunity to work on advanced AI models and link them with the challenges we face when working on locations extracted from cellular networks. Interesting and successful topic, that seemed to also convince people outside the team, as our hackathon work reached the podium of the audience vote, and was even awarded the prestigious “Product Management prize”!
Thanks for reading!