
Memory – Part 6: Optimizing the FIFO and Stack allocators
Introduction
The most used custom allocators at Intersec are the FIFO and the Stack
allocators, detailed in
a previous article.
The stack allocator is extremely convenient, thanks to the
t_scope macro, and the FIFO is well fitted to some of our use
cases, such as inter-process communication. It is thus important for these
allocators to be optimized extensively.
We are two interns at Intersec, and our objective for this 6 week
internship was to optimize these allocators as far as possible. Optimizing
an allocator can have several meanings: it can be in terms of memory overhead,
resistance to contention, performance… As the FIFO allocator is designed to work
in single threaded environments, and the t_stack is thread local,
we will only cover performance and memory overhead.
Tools used
To be able to quickly assess the impact of our changes, we began by writing a quick benchmark that uses the allocator to make a few million allocations and measures the time it takes.
For the FIFO allocator, the scenario is the following: in the first loop,
we request memory for the allocator and we immediately release it. In the
second loop, we loop several times through an array of pointers, and at
each iteration, the pointer is freed (if it is not NULL) and
then reallocated. The effect of this is that there is a constant amount of
memory allocated at all times, and we keep a FIFO behaviour: the first pointer
allocated is also the first freed. The third loop still uses the array of
pointers, but instead of looping through it regularly, it selects a random
one at each iteration, frees it and re-allocates it. This way we still have
a constant amount
of memory allocated, but we lose the FIFO behaviour.
For the stack allocator the scenario is simpler: a recursive function
allocates some memory, calls itself up to a given recursion depth, allocates
some more memory after the recursive call ended and then returns.
The t_scope mechanism ensures that all the memory allocated
by a function is freed when it returns.
To look for performance bottlenecks, we extensively used the linux perf tool which allows to quickly see how our changes affect crucial parameters such as the number of branch misses or cache misses, and where these events originate from. Since the allocation routines are almost flat functions, we needed an insight down to the instruction level.
We also instrumented both allocators to keep track of several statistics
such as the memory allocated, the memory used, the numbers of memory requests,
the number of subsequent calls to mmap() or calloc(),
and the time the different functions (malloc(), free(),
realloc()) take to complete. This instrumentation also allowed us
to check the behaviour of our allocators in real products, and not only in our
benchmark. This instrumentation incrementally gathers all the necessary usage
information, and periodically dumps it into a file.
Using this tool, we have analysed the main memory allocation patterns
in Igloo, the Intersec Geo-Locator. The demonstration program for Igloo has
been used to get a simplified real-world use-case. For both allocators, an
entry in the file dump is issued each 300 simple operations
(malloc(), free(), realloc()),
and at each long operation (memory request from the system, memory page
cleaning…). Feeding only 10,000 events per second for 5 minutes into Igloo
already produces an overwhelming quantity of dumps, around 6GB. Exploiting
this quantity of dumps has been a bit of a challenge, but has provided
some insight into the effective usage of the allocators: for instance, we get
around 100,000 allocations per minute.
The FIFO allocator
The FIFO allocator is relying on large pages of memory allocated through
mmap().
The pages are split into variably-sized blocks as requested. Each block
maintains a reference to the page it belongs to (actually the offset of the
block in the page), as well as its size. The FIFO pool keeps a reference to
the current page as well as a free page, which is not always set but is used
to reduce the number of page deallocation / reallocation operations.
typedef struct mem_page_t {
uint32_t used_size; /* size used in the page */
uint32_t used_blocks; /* number of blocks not freed yet */
size_t size; /* size of area[] */
void *last; /* last result of an allocation */
byte __attribute__((aligned(8))) area[]; /* space to create blocks into */
} mem_page_t;
typedef struct mem_block_t {
uint32_t page_offs; /* address of this minus address of containing page */
uint32_t blk_size; /* size of area[] */
byte area[]; /* user data goes here */
} mem_block_t
With this structure, the behaviour of the 3 main functions
(alloc(), realloc(), free())
is straightforward:
- For
alloc(): if there is enough space in the current page, return a pointer to the beginning of the free space in the current page (fast path), else allocate a new page. - For
realloc(): if the new size is smaller than the original size, return the same pointer. Else if the pointer we are reallocating is the last block of its frame and there is enough space in the frame, return the same pointer too, else allocate a new block, copy the memory from the old block to the new and free the old one. - For
free(): decrease the number of blocks in the containing page. If this number is zero, destroy the page.
The FIFO allocator always returns memory initialized to zero. It also aligns all memory blocks on multiples of at least 8 bytes.
For these three functions, the fast code path (without operations on pages) is extremely fast, and the slow path is not supposed to happen too often (as long as the default page size is big enough to hold a reasonable number of allocations, which is the responsibility of the owner of the pool) but as we will see, there was still room for improvement. Trying to reduce the frequency of the slow paths and increasing the speed of the fast path allowed us to make the FIFO allocator 30% faster than it originally was.
Page management
The most significant improvements we have made to the FIFO allocator were achieved by improving the page management policy. What was initially done was:
- The pool is created without a page (
current = NULL) - When allocating or reallocating, if there is not enough room in the current page, request a new page.
- When freeing, if we are freeing the last block of a page:
- If the page is the current one, set current to
NULL - If there is already a freepage, delete our page, else reset the page and save it as freepage.
- If the page is the current one, set current to
Requests for a new page are performed through mem_page_new(),
which returns the freepage if it exists, and allocates a new one otherwise.
An important thing to note is that the free()
function is responsible for the deletion of unused pages: the pool doesn’t
keep references to any page unless it is the current page. Instead, each page
tracks the number of blocks still alive in it, and when all blocks are freed,
this count reaches zero and the page must be freed.
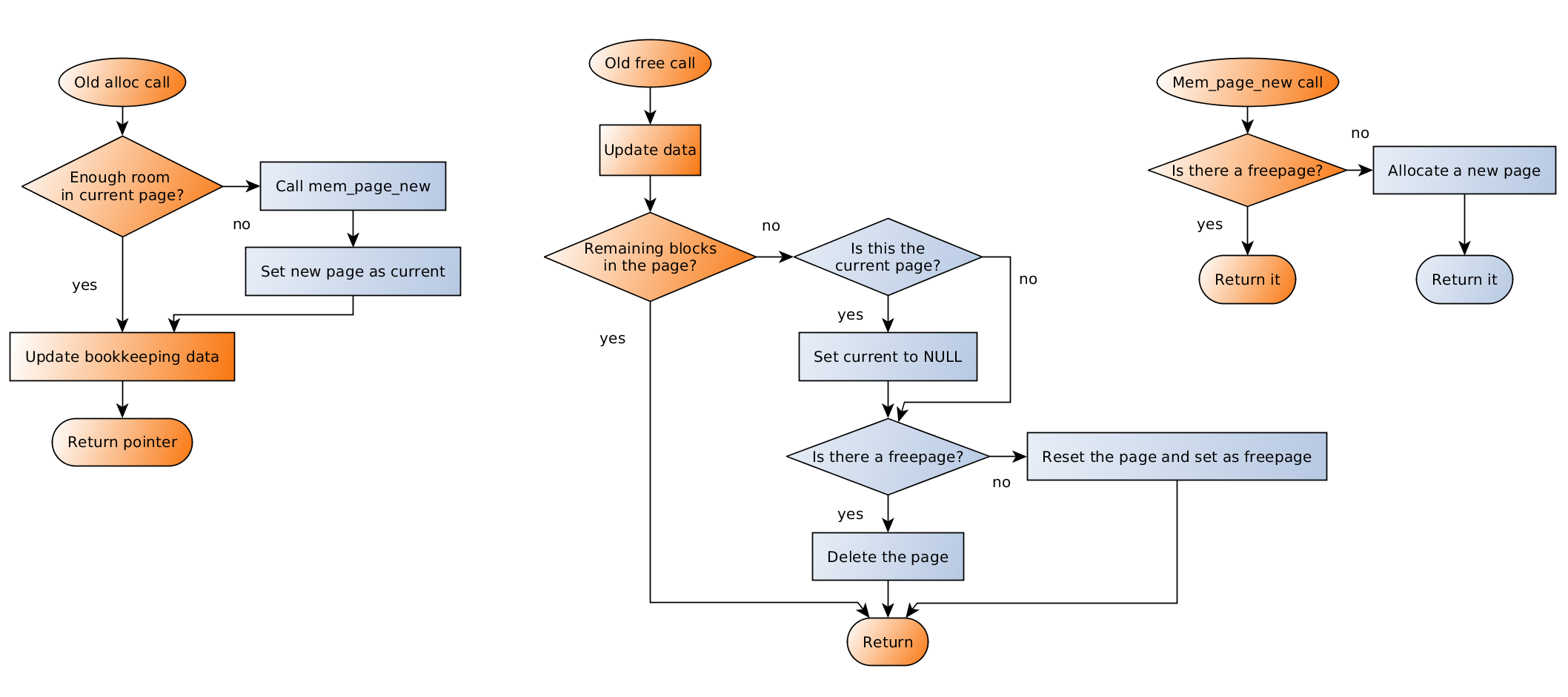
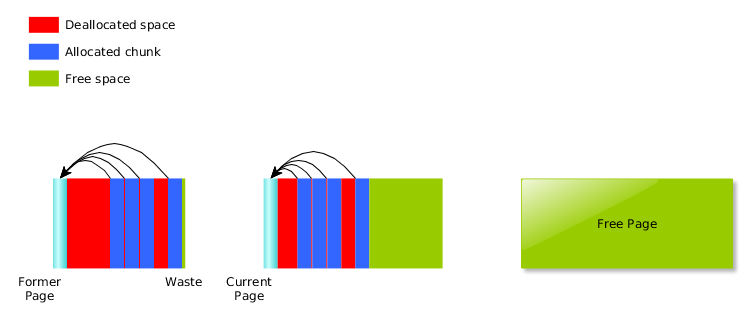
alloc()
and free() – Click image to enlargeThis scheme is good, but it has several drawbacks: for instance, let’s
consider the case where there is only one pointer allocated at a time. When
it is freed, we set current to NULL, and then we reset the page
(assuming that there is no freepage, which is the case after the first
iteration), i.e. we memset()
the used space of the page to zero. As a consequence, each time we want to
allocate, we need to fetch the free page first. This means that in this case,
all calls trigger slow path runs.
To circumvent it, we gave the current page a special treatment in
free(): if its last block is freed, we do nothing, so that the
next allocations will keep filling it. However, we also had to add an extra
check in the
slow path of alloc(): when the current page is out of space,
if it turns out that there is no alive block in it, we have to reset it
(and then we can reuse it).
This has the side effect that current is
never NULL once the first page has been created. If we allocate
the first page at the creation of the pool, we can be sure that current will never be NULL, thus we can remove this check from the fast path of both alloc() and realloc().
Another improvement that was made, which is closer to a trade-off between memory overhead and performance, is the following: if a page becomes available, and we already have a freepage, instead of deleting it straight away, we check the remaining space available in the current page: if the free space in the current page is less than 1/8th of the size of the available page, we immediately replace it with the available page. This doesn’t incur a raw performance gain in the benchmark, but it tackles a bad behaviour that we spotted in a product where a page would be deleted just before a new one was allocated. This change greatly reduces the page allocation frequency in this case.
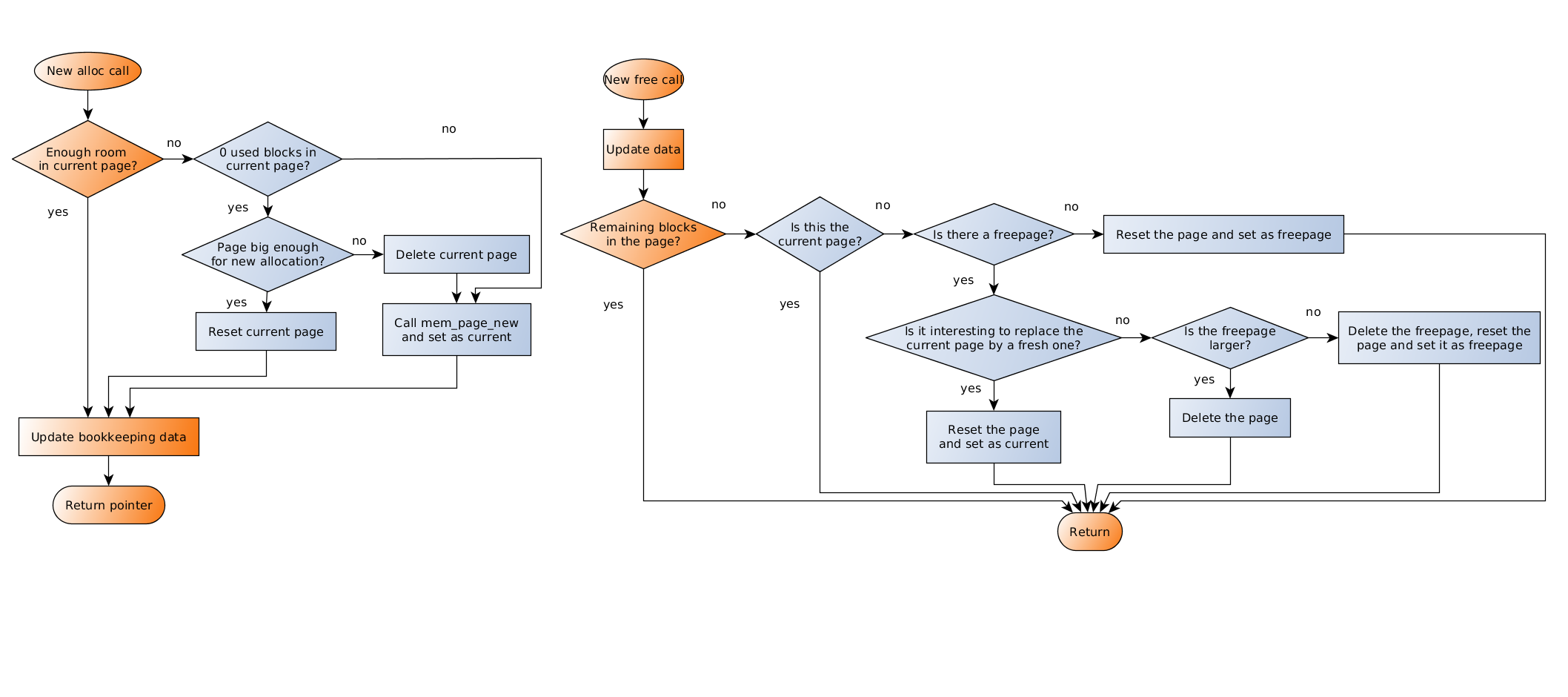
alloc()
and free()
– Note: mem_page_new() has not changed
– Click image to enlargePage allocation
The allocation of new pages was initially done through calls to
mmap(), which always returns memory initialized to zero.
However, using calloc()
turned out to be significantly faster. Here are the results of the time
it took for our benchmark to complete, depending on page size, for
mmap() and calloc():
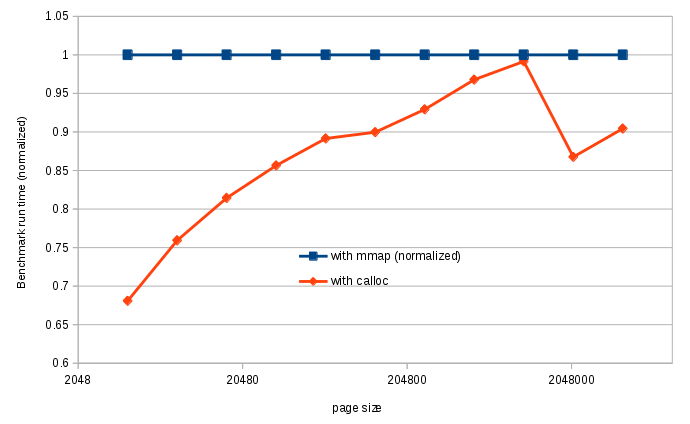
calloc() and mmap()
for page allocationBoth functions are approximately as fast for 1MiB pages,
which (according to
the malloc()
source) is the threshold above which malloc()
switches tommap() . But surprisingly, for bigger pages
calloc() is again faster than mmap(),
so we switched to calloc() for all page sizes.
The default page size being 64KiB, this simple switch made our
benchmark run faster by 10%.
Other optimisations
A conventional optimisation technique that we went through is
structure packing. Because of how the memory
pools are managed, each pool structure has to inline a 40-byte
mem_pool_t
structure, which leaves 24 bytes on the first cache line for the specific
pool data. The current and freepage pointers consume 16 of these 24 bytes.
The FIFO pool has a specific way of being destroyed: if there is still
allocated memory in the pool when we try to delete it, it stays alive until
all the memory is freed. Because of this, it has to keep a boolean indicating if the destructor has been called (and forbidding allocations if it is the case) and the number of pages allocated. It also keeps the default page size which is configured at the creation of
the pool. Moreover, it keeps track of the total memory allocated, and of
the currently used memory, which are needed by statistics reporting functions.
This makes a lot of information for the 8 remaining bytes, however among these
members, the only ones that are used in the fast paths are the
alive boolean and the occupied integer.
occupiedcan’t be stored on 4 bytes, because it may very
well exceed 4GiB (it often does so in the benchmark), but if we use an
8-byte integer, then there is no room left for alive on the first cache
line. The fastest solution here was to use bitfields: 63 bits for
occupied and 1 for alive. This gave a ~3% speed improvement
in the bench.
The resulting structure is the following:
typedef struct mem_fifo_pool_t {
mem_pool_t funcs;
mem_page_t *freepage;
mem_page_t *current;
size_t occupied : 63;
bool alive : 1;
/* cache line 1 end */
size_t map_size;
uint32_t page_size;
uint32_t nb_pages;
#ifdef MEM_BENCH
/* Instrumentation */
mem_bench_t mem_bench;
dlist_t pool_list;
#endif
} mem_fifo_pool_t;
Another optimisation we did is actually quite funny: consider the two
code blocks below, taken from alloc():
...
/* Must round size up to keep proper alignment */
size = ROUND_UP((unsigned)size + sizeof(mem_block_t), 8);
page = mfp->current;
if (mem_page_size_left(page) < size) {
...
...
page = mfp->current;
/* Must round size up to keep proper alignment */
size = ROUND_UP((unsigned)size + sizeof(mem_block_t), 8);
if (mem_page_size_left(page) < size) {
...
Can you tell which one is the fastest? No you can’t, you would need to
compile the whole code to do so. The thing is that thanks to the
perf tool, we saw that the assembly instruction corresponding to page = mfp->current; was taking a lot of time. We tried moving it around, and we saw that putting it before the size assignment yielded a 2% improvement in the bench. Upon closer inspection of the assembly code generated, we saw that this modification completely changed GCC’s register allocation, and thus reduced register interlock in this portion of the code.
The Stack allocator
The Stack allocator, unlike the FIFO allocator, is frame-based:
allocations are grouped in frames, to allow batch deallocation.
Frames are stacked in a LIFO ordering. Prior to a group of allocations,
one must push a frame into the allocator, and pop it to free the group.
The frame object records all the bookkeeping information for allocations.
It still shares some properties with the FIFO allocator, being block-based
(a block here denotes what the FIFO allocator called a page). This way,
it can achieve very fast size-agnostic allocations. The model is simple: the
frame holds the current position in the block. Upon a memory request,
we just need to bump this pointer forward. Thanks to the frame-based model,
deallocation is almost free, we just need to pop the last frame. The
allocator will recover its exact state, saved by the matching push. The
third meaningful operation is realloc().
General purpose reallocation of an arbitrary memory chunk is in general
difficult and slow. However, the block-based model allows a very useful
case: reallocating the last allocation is almost free. We just need to
update the position pointer.
typedef struct mem_stack_frame_t {
mem_stack_frame_t *prev; /* previous frame */
mem_stack_blk_t *blk; /* current active block */
uint8_t *pos; /* allocation position */
uint8_t *last; /* address of last allocation */
} mem_stack_frame_t;
uint8_t *sp_alloc(mem_stack_frame_t *frame, size_t size)
{
uint8_t *res = frame->pos;
uint8_t *top = frame->pos + size; /* check for sufficient space */
if (top >= blk_end(frame->blk)) {
/* get more memory (slow path) */
}
frame->pos = top;
return res;
}

Since the fast path is already very efficient (16 cycles), the actual improvement resides mostly in controlling the frequency of slow paths, i.e. allocation of new blocks from system.
Block allocation policy
The block allocation policy is constrained by the need for very fast
deallocations. This incurs that almost all the block handling is done on
demand, at allocation time. The general block management uses a simple
list of blocks. At all times, all the blocks before the current frame’s
are in use, and all the latter blocks are free. When a block is required,
the list is traversed. If no suitable block is found a new one is allocated.
Because of the typical size of the blocks (at least 64KiB), the creation of
new blocks is made via a call to the libc’s malloc(), which in
turn yields a call to mmap()
. This incurs a substantial latency, so it is important to reuse the blocks.
This reduces memory consumption, memory fragmentation and allocation time.
Compared to the fast path of the allocator, searching a new block is very time-consuming, and creating one is all the more. A straightforward manner to reduce the penalty is to be eager with resizes. For instance, take the following diagram: the current frame (Frame 2) owns an almost full block, so pushing a new frame will require a new block. When pushing Frame 3, the code used to consider that it must not alter the former, so Frame 2 still points to Block A, and Frame 3 to Block B. After several operations, this frame will be popped, and this last block will be put back on free list, back to square one. Then, another frame will be pushed, and require that same free block. This forgetful behaviour is not the most efficient.
A first step towards solving this is to always update the current frame when a block is added. This way, on the example below, Frame 2 remembers it will soon need Block B, and avoids repeated block fetching. This furthermore allows to save a branch in the allocation code. A second step is to add speculative block replacement: whenever a block is added to the top frame, it can conditionally be added to the previous frames too.
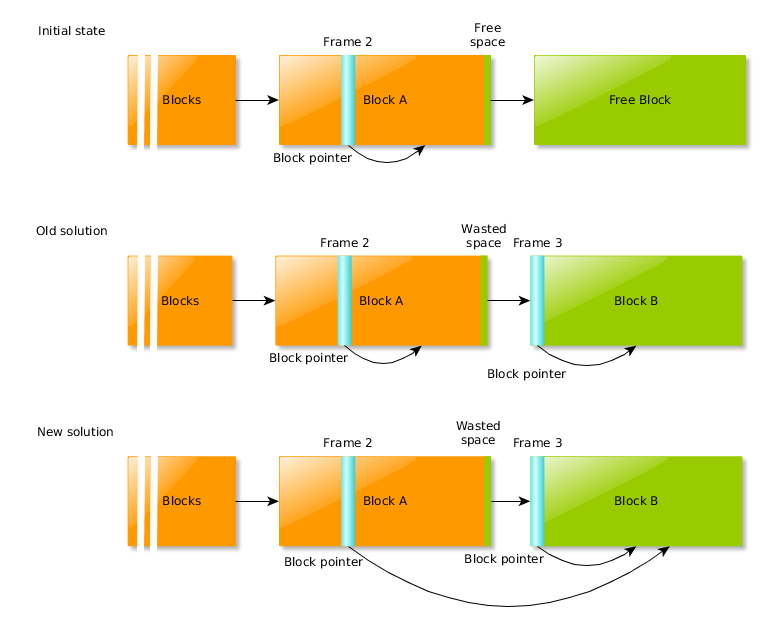
Block searching
When a block was needed (slow path), the block search was greedy:
- visit the free blocks list, if the block is big enough return it, else destroy it
- if no suitable block is found, create a new one
Actually, this scheme just considered that the small blocks will always be too small for further allocations. While this keeps memory usage bounded and aims at reducing the fragmentation, it relies on the assumption of fairly regular request sizes. This behaviour is deadly when an oversized allocation slips in. For instance, this pattern of allocation:
static void worst_case(int depth)
{
for (int i = 0; i < depth; i++) {
t_scope;
byte* mem;
{ /* allocate and free a bunch of small objects */
t_scope;
for (int k = 0; k < 20000; k++) {
mem = t_new_raw(byte, 100);
}
}
/* allocate an oversized block */
mem = t_new_raw(byte, 80000 + PAGE_SIZE * depth);
}
}
Using our instrumentation of the allocator, we created the following
graph, plotting the current memory allocated from the t_stack
(black) and the memory available in blocks (purple). Horizontal axis is the
number of file dumps, vertical axis is the size in bytes.
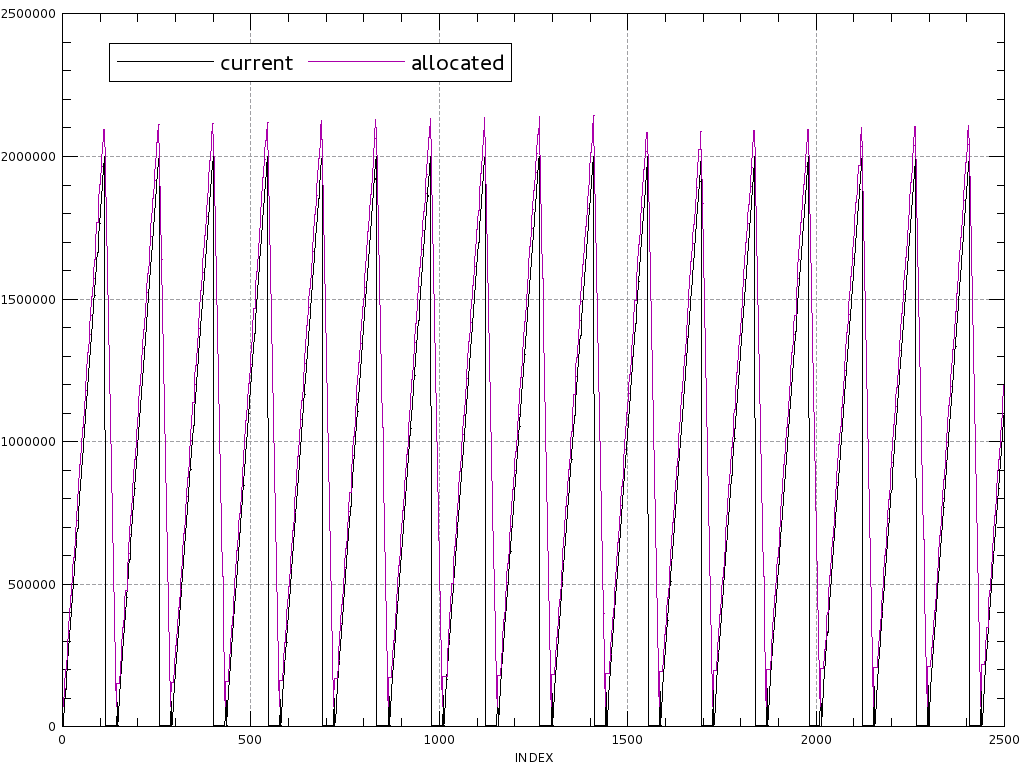
worst_case(),
initial depth 20, truncated at 2500 allocator operations.
Cumulated size of block allocations: 35MiBAnalysing this graph, we observe that the allocator allocates a bunch of small blocks for the first scope, puts them on the free list when popping the frame, wipes everything to create a 80kB+ block, reallocates a similar bunch of small blocks, and repeat this all over. This is clearly suboptimal.
In order to avoid this, we chose to stop the block destruction as soon as we reached the requested size. This keeps the bounded memory usage and still reduces memory fragmentation. On this very example, the gain in time is around 30%.
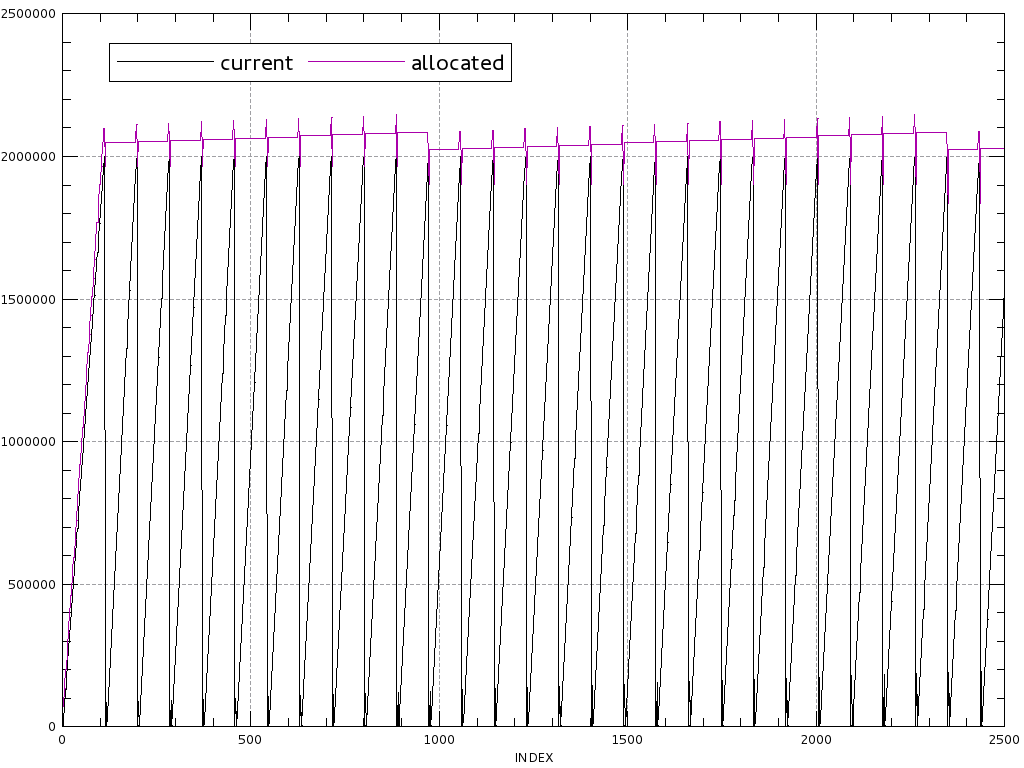
worst_case(), initial depth = 20, truncated at 2500 allocator
operations. Cumulated size of block allocations: 7.5MiBBlock sizing
In order to bound the block switch frequency, those are sized proportionally to average of the size of the requests. A newly allocated block must be at least 64 times the mean allocation size as computed below.
typedef struct average_t {
size_t sum;
size_t nb;
} average_t;
void average_update(average_t *av, size_t request)
{
/* truncate too big requests */
if (request < (128 << 20)) { if (av->sum + request < av->sum
|| av->nb >= UINT16_MAX)
{
av->sum /= 4;
av->nb /= 4;
}
av->sum += request;
av->nb += 1;
}
}
size_t average_get(average_t *av)
{
return av->sum / av->nb;
}
This method for computation is great for use in the allocator. It uses basic integer operations only (addition, comparison and shift), and be updated in a few clock cycles, and most of all is smooth. The resulting average converges roughly at the same speed than an exponential moving average with decay 1/27279, but is 25% smoother (computed from the expected deviation after an new input value).
Still, some parts of this algorithm could be elided by some maths. First,
the maximum allocation allowed is 1GiB. This check is primarily made for
sanity reasons, to avoid devious allocations caused by
unchecked overflow. Since av->nb is smaller than
UINT16_MAX, av->sum will always be smaller than
1GiB * UINT16_MAX < UINT64_MAX. Hence, the overflow check is
always false.
Removing this check does not improve anything, it just removes a jump
instruction that was always predicted. The other test we may want to remove
is the truncation to 128MiB. A probability analysis shows that the expected
oversize for a single peak pis roughly equal
to p / 550,
for any average request size. After an allocation of 1GiB, the expected
overhead in block size will be 2MB. This is fairly tractable after a 1GiB
allocation, so the truncation can be removed.
Fast path improvement
Besides being already very efficient, the preferred path for allocation contained some overhead in the way alignment was computed.
Memory alignment is a central performance problematic. Most processors
access memory with granularity of a word, which means that any read or store
will at least fetch this size. From the way computer memory is handled, these
accesses work best when addresses are word-aligned. Moreover, some recen
t instructions (and some old architectures) do require aligned operands
(vector operations in SSE2 require 128-bit alignment).
The easiest way to fulfill alignment requirements in an allocator is to keep uniform alignment for all the allocated objects. This takes the form of rounding up the size to next boundary, an operation happily optimized by the compiler, since the alignment is known at compile time. Although being most efficient, the memory overhead of this scheme can be unbearable: for 16-byte alignment, allocating a single integer takes four times the size!
This behaviour has fortunately been changed in Intersec allocators in favour of on-demand alignment. This model requires to round up the returned pointer to demanded boundaries. In the original code, both the returned address and the size were rounded up. This accounts for unnecessary checking:
- for sizes computed with
sizeof(), the alignment is guaranteed by the C language (C99 standard, paragraph 6.5.3.4/3) - the processor only cares about address alignment
The key for efficient computation is to use the fact that alignment is
always a power of two. The choice in implementation resides in the storage
of the alignment boundary: either in full form (like the output
of alignof() operator, a power of two), or in logarithmic form
(the position of the bit).
/* Alignment computation */
uintptr_t full_mem_align(uintptr_t mem, size_t align)
{
assert (!(align & (align - 1))); /* fire if not a power of two */
return (mem + align - 1) & (-align);
}
uintptr_t log_mem_align(uintptr_t mem, unsigned logalign)
{
size_t bitmask_le = (1 << logalign) - 1;
size_t bitmask_ge = (size_t)-1 << logalign;
return (mem + bitmask_le) & bitmask_ge;
}
The full form has two advantages: first, it requires a smaller and simpler assembly, faster to execute, and it does not need to compute the logarithm of the alignment. Eventually, benchmarking shows a 9% improvement in the allocation code.
realloc()
In this kind of block-based allocator, the realloc()
operation for last allocated block is very cheap. Indeed, at each allocation,
we record the returned address. At realloc()
time, it is just necessary to bump the position pointer a little farther.
Since the work on the block allocation policy already impacts the
realloc() function, the only part where improvements can be made
is the realloc() code itself.
We followed a logic of branch-elimination on the function. The most used path is in red on the graph below. The typical use of this function is the growing of dynamic arrays: it is expected to be most efficient. This refactoring allows for better branch optimization, and results in a 10% gain in reallocation speed.
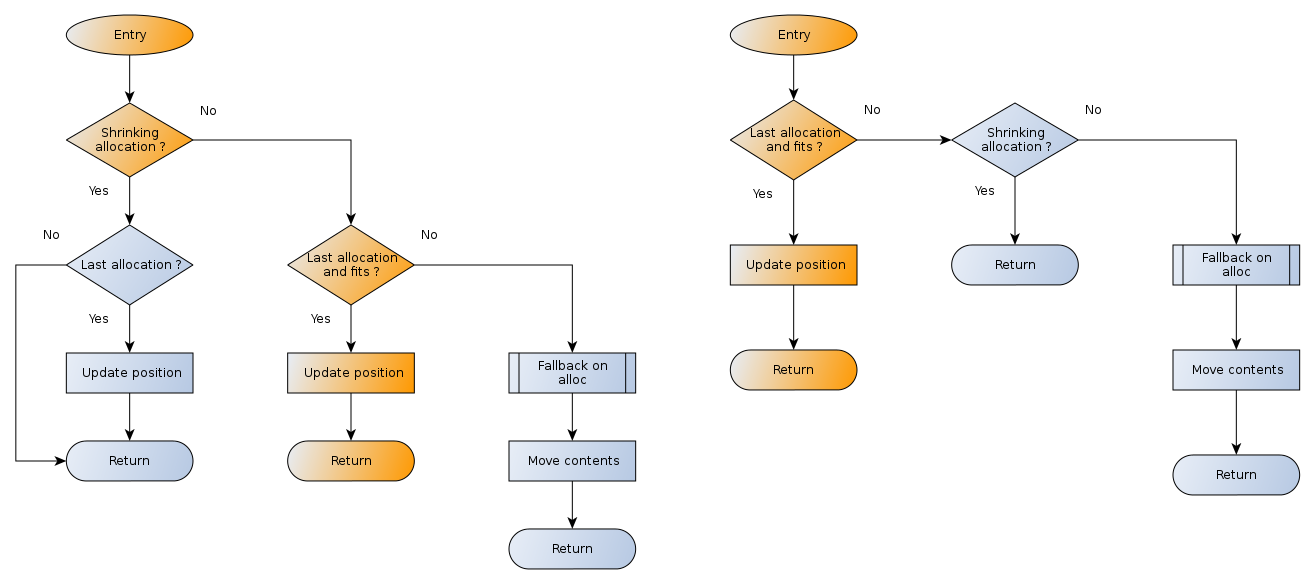
realloc() code path
- Click image to enlargeOverall gains
In order to evaluate the consequences of our work on the stack allocator
, we considered benchmarking both the original and our final versions of the
code. Measuring raw allocation speed for different
allocation / deallocation ratios show a consistent 17% gain. Still, this
benchmark only considers a very regular allocation pattern, and does not
account for exceptional use cases like the worst_case()
function above. Thanks to this observation, this former gain is more
of a lower bound on the improvements.
Conclusion
These allocators were already quite efficient, but we still managed to find ways to improve them, the most significant of which are detailed in this article. By grabbing a few percent here and there, we eventually improved the overall performance of the two allocators by around 20-30%, depending on the use cases. It was a challenging task, because of the complexity of the matter as well as the fact that we had to dive into a particularly developed code base.
We learnt a lot of things during these six weeks, and we are particularly happy to have done so at Intersec, where skill meets cheerfulness.
Camille Gillot & Aloÿs Augustin, interns @ Intersec
Thanks to Jonathan Squirawski, our tutor, for his patience and careful
review.
Thanks to Florent Bruneau, for his advice and his review.