
Memory - Part 2: Understanding Process memory
From Virtual to Physical
In the previous article , we introduced a way to classify the memory a process reclaimed. We used 4 quadrants using two axis: private/shared and anonymous/file-backed. We also evoked the complexity of the sharing mechanism and the fact that all memory is basically reclaimed to the kernel.
Everything we talked about was virtual. It was all about reservation of memory addresses, but a reserved address is not always immediately mapped to physical memory by the kernel. Most of the time, the kernel delays the actual allocation of physical memory until the time of the first access (or the time of the first write in some cases)… and even then, this is done with the granularity of a page (commonly 4KiB). Moreover, some pages may be swapped out after being allocated, that means they get written to disk in order to allow other pages to be put in RAM.
As a consequence, knowing the actual size of physical memory used by a process (known as resident memory of the process) is really a hard game… and the sole component of the system that actually knows about it is the kernel (it’s even one of its jobs). Fortunately, the kernel exposes some interfaces that will let you retrieve some statistics about the system or a specific process. This article enters into the depth of the tools provided by the Linux ecosystem to analyze the memory pattern of processes.
On Linux, those data are exposed through the /proc file-system and more
specifically by the content of /proc/[pid]/. These directories (one per
process) contain some pseudo-files that are API entry points to retrieve
information directly from the kernel. The content of the /proc directory is
detailed in proc(5) manual page (this content changes from one Linux version to
another).
The human front-end for those API calls are tools such as procps (ps,
top, pmap…). These tools display the data retrieved from the kernel with
little to no modification. As a consequence they are good entry points to
understand how the kernel classifies the memory. In this article we will
analyze the memory-related outputs of top and pmap.
top: process statistics
top is a widely known (and used) tool that allows monitoring the system. It
displays one line per process with various columns that may contain CPU
related, memory related, or more general information.
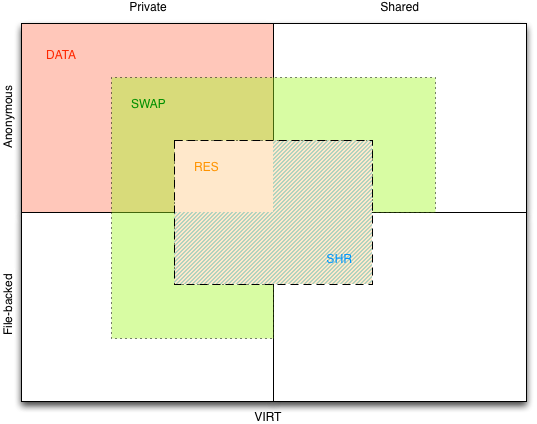
When running top, you can switch to the memory view by pressing G3. In that
view, you will find, among others, the following columns: %MEM, VIRT, SWAP,
RES, CODE, DATA, SHR. With the exception of SWAP, all these data are extracted
from the file /proc/[pid]/statm that exposes some memory related statistics.
That file contains 7 numerical fields: size (mapped to VIRT), resident (mapped
to RES), share (mapped to SHR), text (mapped to CODE), lib (always 0 on Linux
2.6+), data (mapped to DATA) and dt (always 0 on Linux 2.6+, mapped to nDrt).
Trivial columns
As you may have guessed, some of these columns are trivial to understand.
VIRT is the total size of the virtual address space that has been reserved by
the process so far. CODE is the size of the executable code of the binary
executed by the process. RES is the resident set size, that is the amount of
physical memory the kernel considers assigned to the process. As a direct
consequence, %MEM is strictly proportional to RES.
The resident set size is computed by the kernel as the sum of two counters. The
first one contains the number of anonymous resident pages (MM_ANONPAGES), the
second one is the number of file-backed resident pages (MM_FILEPAGES). Some
pages may be considered as resident for more than one process at once, so the
sum of the RES may be larger than the amount of RAM effectively used, or even
larger than the amount of RAM available on the system.
Shared memory
SHR is the amount of resident sharable memory of the process. If you remember
well the classification we made in the previous article, you may suppose this
includes all the resident memory of the right column. However as already
discussed, some private memory may be shared too. So, in order to understand
the actual meaning of that column, we must dig a bit deeper in the kernel.
The SHR column is filled with the shared field of /proc/[pid]/statm which
itself is the value of the MM_FILEPAGES counter of the kernel, which is one of
the two components of the resident size. This just means that this column
contains the amount of file-backed resident memory (thus including quadrant 3
and 4).
That’s pretty cool… however remember quadrant 2: shared anonymous memory does
exist… the previous definition only includes file-backed memory… and running
the following test program shows that the shared anonymous memory is taken into
account in the SHR column:
#include <sys/mman.h>
#include <unistd.h>
#include <stdint.h>
int main()
{
/* mmap 50MiB of shared anonymous memory */
char *p = mmap(NULL, 50 << 20, PROT_READ | PROT_WRITE,
MAP_ANONYMOUS | MAP_SHARED, -1, 0);
/* Touch every single page to make them resident */
for (int i = 0; i < (50 << 20) / 4096; i++) {
p[i * 4096] = 1;
}
/* Let us see the process in top */
sleep(1000000);
return 0;
}
top indicates 50m in both the RES and the SHR columns (You can try running the
same program with no loop (or with a shorter loop) and see how the kernel
delays the loading of the pages in physical memory.)…
This is due to a subtlety of the Linux kernel. On Linux, a shared anonymous map
is actually file-based. The kernel creates a file in a tmpfs (an instance of
/dev/zero). The file is immediately unlinked so it cannot be accessed by any
other processes unless they inherited the map (by forking). This is quite
clever since the sharing is done through the file layer the same way it’s done
for shared file-backed mappings (quadrant 4).
A last point, since private file-backed pages that are modified don’t get
synced back to disk, they are not file-backed anymore (they are transferred from
MM_FILEPAGES counter to MM_ANONPAGES). As a consequence, they don’t account in
the SHR anymore.
Note that the man page of top is wrong since it states that SHR may contain
non-resident memory: the amount of shared memory available to a task, not all
of which is typically resident. It simply reflects memory that could be
potentially shared with other processes.
Data
The meaning of the DATA column is quite opaque. The documentation of top states
“Data + Stack”… which does not really help since it does not define “Data”.
Thus we’ll need to dig once again into the kernel.
That field is computed by the kernel as a difference between two variables:
total_vm which is the same as VIRT and shared_vm. shared_vm is somehow
similar to SHR in that it shares the definition of the shareable memory, but
instead of only accounting the resident part, it contains the sum of all
addressed file-backed memory. Moreover, the count is done at the mapping level,
not the page one, thus shared_vm does not have the same subtlety as SHR for
the modified private file-backed memory. As a consequence shared_vm is the
sum of the quadrants 2, 3 and 4. This means that the difference between
total_vm and shared_vm is exactly the content of quadrant 1.
The DATA column contains the amount of reserved private anonymous memory. By
definition, the private anonymous memory is the memory that is specific to the
program and that holds its data. It can only be shared by forking in a
copy-on-write fashion. It includes (but is not limited to) the stacks and the
heap ((But we will see later that it only partially contains the data segment
of the loaded executables)). This column does not contain any piece of
information about how much memory is actually used by the program, it just
tells us that the program reserved some amount of memory, however that memory
may be left untouched for a long time.
A typical example of a meaningless DATA value is what happens when a x86_64
program compiled with Address Sanitizer is launched. ASan works by reserving
16TiB of memory, but only use 1 byte of those terabytes per 8-bytes word of
memory actually allocated by the process. As a consequence, the output of top
looks like this:
3 PID %MEM VIRT SWAP RES CODE DATA SHR COMMAND
16190 0.687 16.000t 0 56056 13784 16.000t 2912 zchk-asan
Note that the man page of top is once again wrong since it states that DATA is
the amount of physical memory devoted to other than executable code, also known
as the ‘data resident set’ size or DRS; and we just saw that DATA has no link
at all with resident memory.
Swap
SWAP is somehow different from the other ones. That column is supposed to
contain the amount of memory of the process that gets swapped out by the
kernel. First of all, the content of that column totally depends on both the
version of Linux and the version of top you are running. Prior to Linux
2.6.34, the kernel didn’t expose any per-process statistics about the number of
pages that were swapped out. Prior to top 3.3.0, top displayed a totally
meaningless information here (but that was in accordance with the man page).
However, if you use Linux 2.6.34 or later with top 3.3.0 or later, that count
is actually the number of pages that were swapped out.
If your top is too old, the SWAP column is filled with the difference
between the VIRT and the RES column. This is totally meaningless because
that difference effectively contains the amount of memory that has been swapped
out, but it also includes the file-backed pages that get unloaded or the pages
that are reserved but untouched (and thus have not been actually allocated
yet). Some old Linux distributions still have a top with that buggy SWAP
value, among them stands the still widely used RHEL5.
If your top is up-to-date but your kernel is too old, the column will always
contain 0, which is not really helpful.
If both your kernel and your top are up-to-date, then the column will contain
the value of the field VmSwap of the file /proc/[pid]/status. That is
maintained by the kernel as a counter that gets incremented each time a page is
swapped out and decremented each time a page get swapped in. As a consequence
it is accurate and will provide you with an important piece of information:
basically if that value is non-0, this means your system is under memory
pressure and the memory of your process cannot fit in RAM.
The man page describes SWAP as the non-resident portion of a task’s address
space, which is what was implemented prior to top 3.3.0, but has nothing to do
with the actual amount of memory that has been swapped out. On earlier versions
of top, the man page properly explains what is displayed, however the SWAP
naming is not appropriate.
pmap: detailed mapping
pmap is another kind of tool. It goes deeper than top by displaying information
about each separate mapping of the process. A mapping, in that view is a range
of contiguous pages having the same backend (anonymous or file) and the same
access modes.
For each mapping, pmap shows the previously listed options as well as the
size of the mapping, the amount of resident pages as well as the amount of
dirty pages. Dirty pages are pages that have been written to, but have not been
synced back to the underlying file yet. As a consequence, the amount of dirty
pages is only meaningful for mappings with write-back, that is shared
file-backed mappings (quadrant 4).
The source of pmap data can be found in two human-readable files:
/proc/[pid]/maps and /proc/[pid]/smaps. While the first file is a simple
list of mappings, the second one is a more detailed version with a paragraph
per mapping. smaps is available since Linux 2.6.14, which is old enough to be
present on all popular distributions.
pmap usage is simple:
pmap [pid]: display the content of the/proc/[pid]/maps, but removes theinodeanddevicecolumns.pmap -x [pid]: this enriches the output by adding some pieces of information from/proc/[pid]/smaps(RSSandDirty).- since
pmap3.3.4 there are-Xand-XXto display even more data but there are Linux specific (moreover this seems to be a bit buggy with recent kernel versions).
Basic content
The pmap utility finds its inspiration in a similar command on Solaris and
mimics its behavior. Here is the output of pmap and the content of
/proc/[pid]/maps for the small program given as example for shared anonymous
memory testing:
3009: ./blah
0000000000400000 4K r-x-- /home/fruneau/blah
0000000000401000 4K rw--- /home/fruneau/blah
00007fbb5da87000 51200K rw-s- /dev/zero (deleted)
00007fbb60c87000 1536K r-x-- /lib/x86_64-linux-gnu/libc-2.13.so
00007fbb60e07000 2048K ----- /lib/x86_64-linux-gnu/libc-2.13.so
00007fbb61007000 16K r---- /lib/x86_64-linux-gnu/libc-2.13.so
00007fbb6100b000 4K rw--- /lib/x86_64-linux-gnu/libc-2.13.so
00007fbb6100c000 20K rw--- [ anon ]
00007fbb61011000 128K r-x-- /lib/x86_64-linux-gnu/ld-2.13.so
00007fbb61221000 12K rw--- [ anon ]
00007fbb6122e000 8K rw--- [ anon ]
00007fbb61230000 4K r---- /lib/x86_64-linux-gnu/ld-2.13.so
00007fbb61231000 4K rw--- /lib/x86_64-linux-gnu/ld-2.13.so
00007fbb61232000 4K rw--- [ anon ]
00007fff9350f000 132K rw--- [ stack ]
00007fff9356e000 4K r-x-- [ anon ]
ffffffffff600000 4K r-x-- [ anon ]
total 55132K
00400000-00401000 r-xp 00000000 08:01 3507636 /home/fruneau/blah
00401000-00402000 rw-p 00000000 08:01 3507636 /home/fruneau/blah
7fbb5da87000-7fbb60c87000 rw-s 00000000 00:04 8467 /dev/zero (deleted)
7fbb60c87000-7fbb60e07000 r-xp 00000000 08:01 3334313 /lib/x86_64-linux-gnu/libc-2.13.so
7fbb60e07000-7fbb61007000 ---p 00180000 08:01 3334313 /lib/x86_64-linux-gnu/libc-2.13.so
7fbb61007000-7fbb6100b000 r--p 00180000 08:01 3334313 /lib/x86_64-linux-gnu/libc-2.13.so
7fbb6100b000-7fbb6100c000 rw-p 00184000 08:01 3334313 /lib/x86_64-linux-gnu/libc-2.13.so
7fbb6100c000-7fbb61011000 rw-p 00000000 00:00 0
7fbb61011000-7fbb61031000 r-xp 00000000 08:01 3334316 /lib/x86_64-linux-gnu/ld-2.13.so
7fbb61221000-7fbb61224000 rw-p 00000000 00:00 0
7fbb6122e000-7fbb61230000 rw-p 00000000 00:00 0
7fbb61230000-7fbb61231000 r--p 0001f000 08:01 3334316 /lib/x86_64-linux-gnu/ld-2.13.so
7fbb61231000-7fbb61232000 rw-p 00020000 08:01 3334316 /lib/x86_64-linux-gnu/ld-2.13.so
7fbb61232000-7fbb61233000 rw-p 00000000 00:00 0
7fff9350f000-7fff93530000 rw-p 00000000 00:00 0 [stack]
7fff9356e000-7fff9356f000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
There are a few interesting points in that output. First of all, pmap‘s
choice is to provide the size of the mappings instead of the ranges of
addresses and to add the sum of those sizes at the end. This sum is the VIRT
size of top: the sum of all the reserved ranges of addresses in the virtual
address space.
Each map is associated with a set of modes:
r: if set, the map is readablew: if set, the map is writablex: if set, the map contains executable codes: if set, the map is shared (right column in our previous classification). You can notice thatpmaponly has thesflag, while the kernel exposes two different flags for shared (s) and private (p) memory.R: if set, the map has no swap space reserved (MAP_NORESERVEflag ofmmap), this means that we can get a segmentation fault by accessing that memory if it has not already been mapped to physical memory and the system is out of physical memory.
The first three flags can be manipulated using the mprotect(2) system call
and can be set directly in the mmap call.
The last column is the source of the data. In our example, we can notice that
pmap does not keep the kernel-specific details. It has three categories of
memory: anon, stack and file-backed (with the path of file, and the
(deleted) tag if the mapped file has been unlinked). In addition to these
categories, the kernel has vdso, vsyscall and heap. It’s quite a shame
that pmap didn’t keep the heap mark since it’s important for programmers
(but that is probably in order to be compatible with its Solaris counterpart).
Concerning that last column, we also see that executable files and shared
libraries are mapped privately (but this was already spoiled by the previous
article) and that different parts of the same file are mapped differently (some
parts are even mapped more than once). This is because executable files contain
different sections: text, data, rodata, bss… each has a different meaning and
is mapped differently. We will cover those sections in the next post.
Last (but not least), we can see that our shared anonymous memory is actually
implemented as a shared mapping of an unlinked copy of /dev/zero.
Extended content
The output of pmap -x contains two additional columns:
Address Kbytes RSS Dirty Mode Mapping
0000000000400000 4 4 4 r-x-- blah
0000000000401000 4 4 4 rw--- blah
00007fc3b50df000 51200 51200 51200 rw-s- zero (deleted)
00007fc3b82df000 1536 188 0 r-x-- libc-2.13.so
00007fc3b845f000 2048 0 0 ----- libc-2.13.so
00007fc3b865f000 16 16 16 r---- libc-2.13.so
00007fc3b8663000 4 4 4 rw--- libc-2.13.so
00007fc3b8664000 20 12 12 rw--- [ anon ]
00007fc3b8669000 128 108 0 r-x-- ld-2.13.so
00007fc3b8879000 12 12 12 rw--- [ anon ]
00007fc3b8886000 8 8 8 rw--- [ anon ]
00007fc3b8888000 4 4 4 r---- ld-2.13.so
00007fc3b8889000 4 4 4 rw--- ld-2.13.so
00007fc3b888a000 4 4 4 rw--- [ anon ]
00007fff7e6ef000 132 12 12 rw--- [ stack ]
00007fff7e773000 4 4 0 r-x-- [ anon ]
ffffffffff600000 4 0 0 r-x-- [ anon ]
---------------- ------ ------ ------
total kB 55132 51584 51284
The first one is RSS, it tells us how much the mapping contributes to the
resident set size (and ultimately provides a sum that is the total memory
consumption of the process). As we can see some mappings are only partially
mapped in physical memory. The biggest one (our manual mmap) is totally
allocated because we touched every single page.
The second new column is Dirty and contains the number of pages from their
source. For shared file-backed mappings, dirty pages can be written back to the
underlying file if the kernel feels it has to make some room in RAM or that
there are too many dirty pages. In that case the page is marked clean. For all
the remaining quadrants, since the backend is either anonymous (so no
disk-based back-end) or private (so changes are not available to other
processes), unloading the dirty pages requires writing them to the swap file
(Clean private file-backed pages can also be unloaded, therefore the next time
they get loaded there content may change depending on whether some writes
occurred in the file. This is documented in mmap man page through the
sentence: It is unspecified whether changes made to the file after the mmap()
call are visible in the mapped region.).
This is only a subset of what the kernel actually exposes. A lot more
information is present in the smaps file (which make it a bit too verbose to
be readable) as you can see in the following snippet:
00400000-00401000 r-xp 00000000 08:01 3507636 /home/fruneau/blah
Size: 4 kB
Rss: 4 kB
Pss: 4 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 4 kB
Private_Dirty: 0 kB
Referenced: 4 kB
Anonymous: 0 kB
AnonHugePages: 0 kB
Swap: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Locked: 0 kB
00401000-00402000 rw-p 00000000 08:01 3507636 /home/fruneau/blah
Size: 4 kB
Rss: 4 kB
Pss: 4 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 4 kB
Referenced: 4 kB
Anonymous: 4 kB
AnonHugePages: 0 kB
Swap: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Locked: 0 kB
7f55c4dd2000-7f55c7fd2000 rw-s 00000000 00:04 8716 /dev/zero (deleted)
Size: 51200 kB
Rss: 51200 kB
Pss: 51200 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 51200 kB
Referenced: 51200 kB
Anonymous: 0 kB
AnonHugePages: 0 kB
Swap: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Locked: 0 kB
Adding pmap‘s output to a bug report is often a good idea.
More?
As you can see, understanding the output of top and other tools requires some
knowledge of the operating system you are running. Even if top is available
on various systems, each version is specific to the system it runs on. For
example, on OS X, you will not find the RES, DATA, SHR… columns, but
instead some named RPRVT, RSHRD, RSIZE, VPRVT, VSIZE (note that those
names are somehow a bit less opaque than Linux ones). If you want to dive a bit
deeper in Linux memory management, you can read the mm/ directory of the
source tree, or traverse Understand the Linux
Kernel
.
Because this post is quite long, here is a short summary:
top‘s man page cannot be trusted.top‘sRESgives you the actual physical RAM used by your process.top‘sVIRTgives you the actual virtual memory reserved by your process.top‘sDATAgives you the amount of virtual private anonymous memory reserved by your process. That memory may or may not be mapped to physical RAM. It corresponds to the amount of memory intended to store process specific data (not shared).top‘sSHRgives you the subset of resident memory that is file-backed (including shared anonymous memory). It represents the amount of resident memory that may be used by other processes.top‘sSWAPcolumn can only be trusted with recent versions oftop(3.3.0) and Linux (2.6.34) and is meaningless in all other cases.- if you want details about the memory usage of your process, use
pmap.
If you are a fan of htop, note that its content the exact same as top‘s.
Its man page is also wrong or sometimes at least unclear.
Next: Allocating memory
In these two articles we have covered subjects that are (we do hope) of interest for both developers and system administrators. In the following articles we will start going deeper in how the memory is managed by the developer.